Code: https://github.com/GuYuc/WS-DAN.PyTorch
Motivation
弱监督学习
什么是弱监督学习
弱监督是相对监督而言,所谓的监督简单的说就是label,所以监督的强弱就是从label来划分的,弱监督就是data的label并不是很完善的情况,其种类如下:
- 不完整监督: 部分样本label缺失。 即只有训练数据集的一个(通常很小的)子集有标签,其它数据则没有标签。在很多任务中都存在这种情况。例如,在图像分类中,真值标签是人工标注的;从互联网上获得大量的图片很容易,然而由于人工标注的费用,只能标注其中一个小子集的图像。
- 粗粒度监督: 只有粗粒度的标签。 又以图像分类任务为例。我们希望图片中的每个物体都被标注;然而我们只有图片级的标签而没有物体级的标签。比如说你有一张水果的图片,但是你不知道图片中的水果具体是苹果还是梨。
- 不准确监督:给的label包含噪声,甚至是错误的label,比如把“行人”标注为“汽车”。 即给定的标签并不总是真值。出现这种情况的原因有,标注者粗心或疲倦,或者一些图像本身就难以分类。
数据增强
数据增强是常用的增加数据训练数据量的方法,被用来预防过拟合和提高深度学习模型的表现。在计算机视觉领域实践应用中常用的数据增强方法主要有:剪裁、翻转、旋转、比例缩放、位移、高斯噪声以及更高级的增强技术条件型生成对抗网络(Conditional GAN)。
- 剪裁(Crop):从原始图像中随机抽样一部分,然后将此部分调整为原图像大小。这种方法通常也被称为随机剪裁。
- 翻转(Flip):可以对图片进行水平和垂直翻转。
- 旋转(Rotation):对图像按照图像中心进行旋转一定角度,并将大小作为原图的大小。
- 比例缩放(Scale):图像可以向内或者向外缩放。向内缩放后通常图像会小于原图,通常会对超出边界做处内容假设;向外缩放后通常会大于原图,通常会新图中剪裁出一部分。(它和随机剪裁得到对图像具有一定区别,有兴趣可以自己拿一张图片试一下看一下效果)
- 位移(Translation):对同图像中对目标按照x或y方向平移,因为多数情况,我们的目标对象可能出现在图像的任何位置。
- 高斯噪声(Gaussian Noise):当神经网络试图学习高频特征(即非常频繁出现的无意义模式),而这些高频特征对模型提升没有什么帮助的时候发生过拟合(Overfitting)。因此,对这些数据人为加入噪声,使其特征失真,减弱其对模型的影响,高斯噪声就是这种方法之一,
- 条件型生成对抗网络(Conditional GANs):是一种强大的神经网络,能将一张图片从一个领域转换到另一个领域中去,比如改变风景图片的季节、转换图片风格等。
Methods
创新点
- 双线性注意力池化机制(Bilinear Attention Pooling, 下文简称BAP)
- 类center loss的注意力监督机制
- 基于注意力的数据增强策略

Weakly Supervised Attention Learning
训练过程:
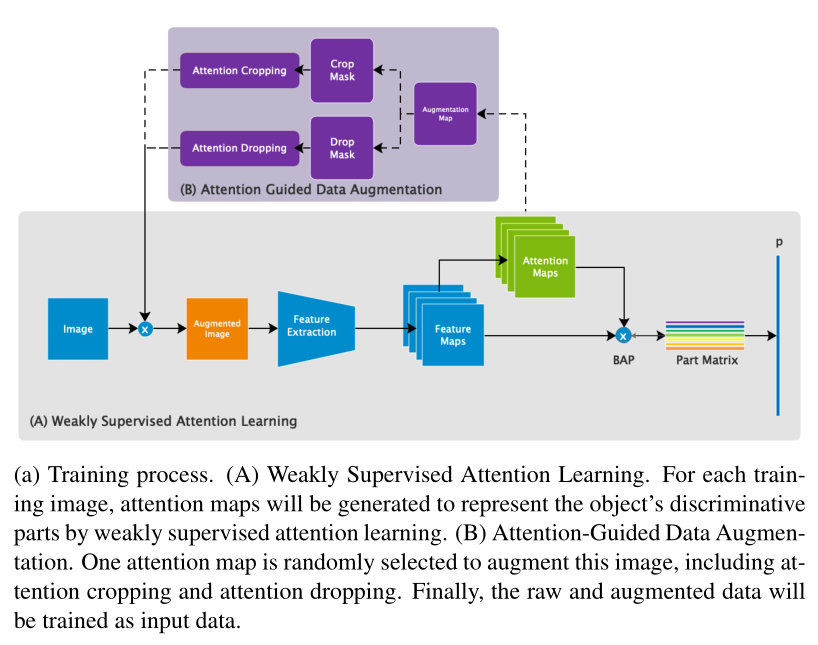
测试过程:
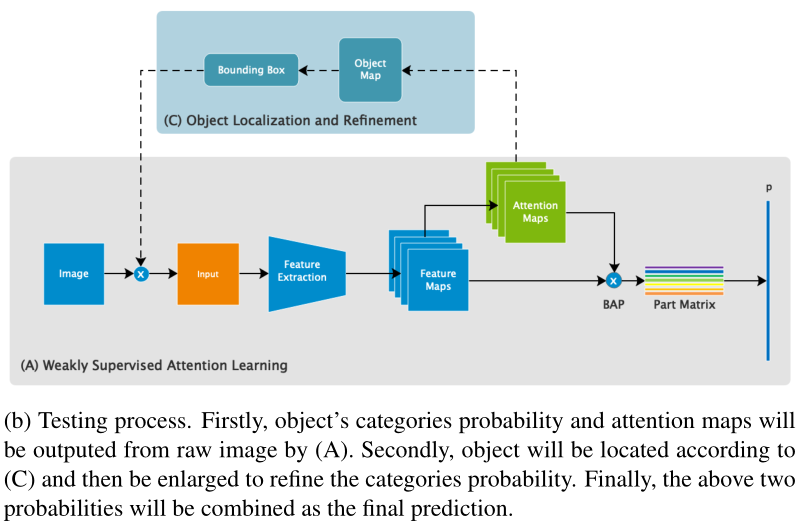
Spatial Representation
采用Attention map来实现注意力机制
\[A=f(F)=\bigcup_{k=1}^{M} A_{k}\]
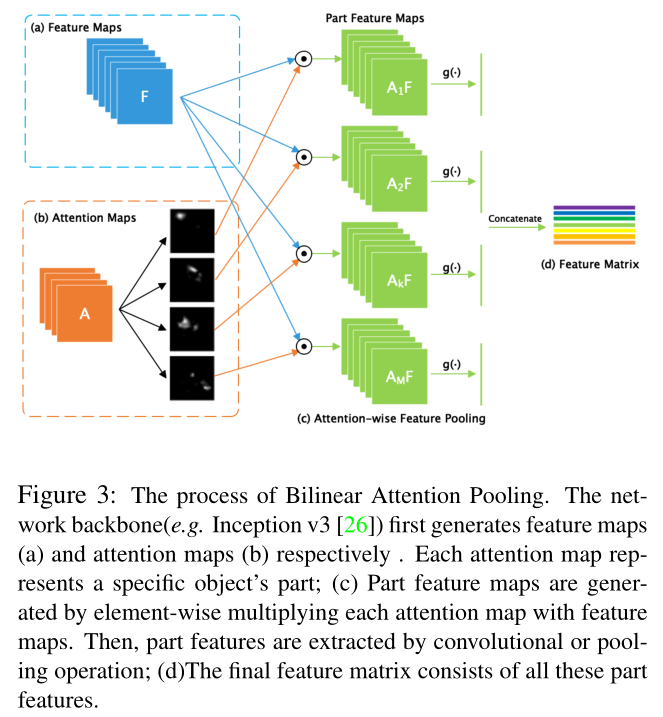
Bilinear Attention Pooling
首先通过网络的主干(如resnet18)部分分别得到特征图(a)和注意力图(b)。每一个注意力图都代表了目标的特定部分。通过对注意力图和特征图的元素点乘得到各个分部特征图,让后利用卷积或者池化处理分部特征图,最后将各个分部特征图结合得到特征矩阵。
Attention Regularization
使用attention center loss, 进行弱监督attention 的学习。
Attention-guided Data Augmentation
Augmentation Map
由Attention Map 生成Augmentation Map,指导后续数据增强。
\[A_{k}^{*}=\frac{A_{k}-\min \left(A_{k}\right)}{\max \left(A_{k}\right)-\min \left(A_{k}\right)}\]
Attention Cropping
使用\(C_{k}\)对图像进行裁剪。
\[C_{k}(i, j)=\left\{\begin{array}{ll} 1, & \text { if } A_{k}^{*}(i, j)>\theta_{c} \\ 0, & \text { otherwise } \end{array}\right.\]
Attention Dropping
为了鼓励attention map表达不同区域,提出了Attention Dropping,擦除部分图像。
\[D_{k}(i, j)=\left\{\begin{array}{ll} 0, & \text { if } A_{k}^{*}(i, j)>\theta_{d} \\ 1, & \text { otherwise } \end{array}\right.\]
Object Localization and Refinement

Experiments
注意力剪裁和随机剪裁的比较: 随机剪裁容易剪裁到图像的背景,而注意力剪裁知道取那些部分会see better。

注意力丢弃和随机丢弃的比较: 随机丢弃可能会将整个目标丢弃或者只丢弃背景部分,而注意力丢弃对剔除目标显著部分和的注意力求具有更高的效率。
