Motivation
我们都知道trick在CNNs中的重要性,但是很少有文章详细讲解他们使用的trick,更少有文章对比各个trick对最后效果影响,这篇文章把CNNs里几种重要的trick做了详细对比,可以认为是一篇在CNNs中使用trick的cookbook。
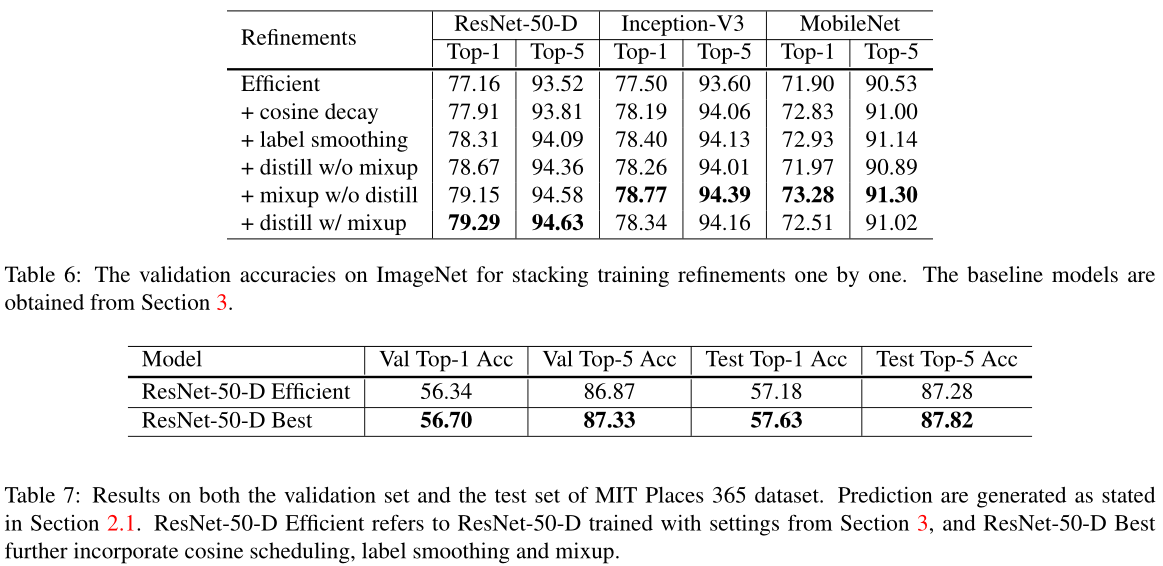
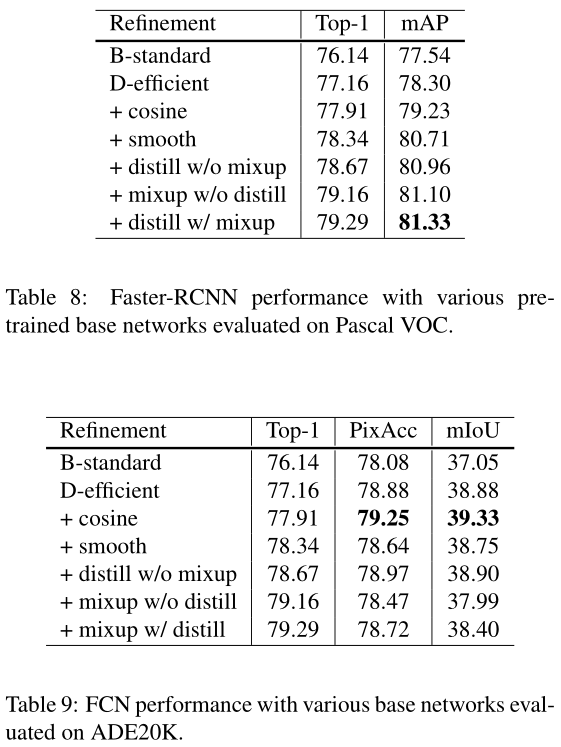
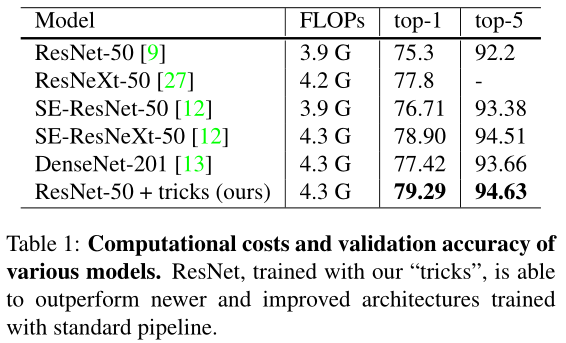
这篇文章的trick有五个方面:model architecture, data augmentation, loss function, learning rate schedule,optimization。总结一句话就是,网络input stem和downsample模块、mixup、label smoothing、cosine learning rate decay、lr warmup、zero γ对网络影响都不小。
Methods
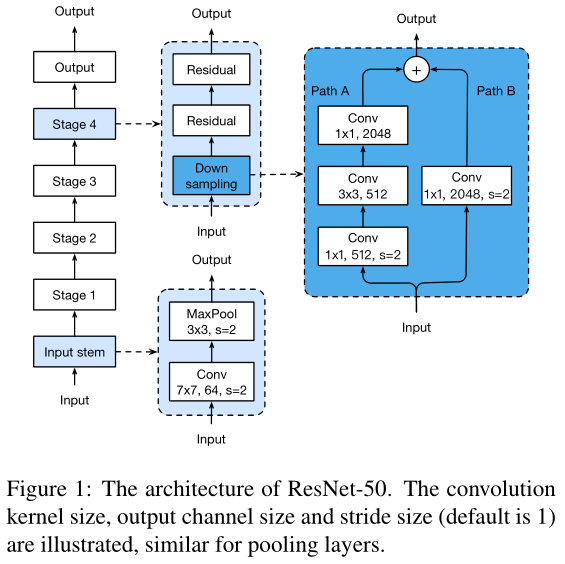
训练网络的Backbone:

训练速度
在训练模型时,共识是batchsize尽可能大一些,有以下优缺点:
- 优点:模型收敛后的精度相对更高
- 缺点:(1)模型收敛速度慢(2)占用更多机器显存
Large-batch training
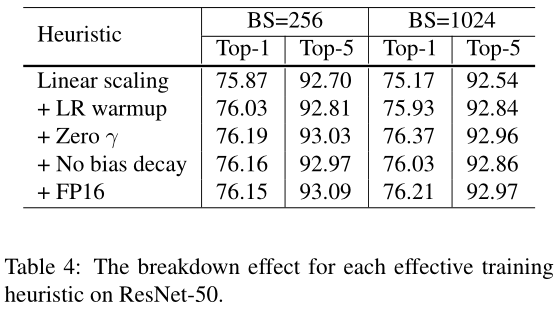
Linear scaling learning rate
增大batch size,单个batch数据中噪声的影响会更小,可以使用大的学习率步长。
Learning rate warmup
训练开始阶段使用较小学习率,训练稳定时换回初始学习率
Zero \(\gamma\)
Resnet网络结构中采用多个残差块结构,其结果为\(x+block(x)\),最后一层通常为batch Norm层,输出为\(\gamma\hat{x}+\beta\),这里将\(\gamma\)和\(\beta\)均置为0,可以使模型在初始阶段更容易训练。
No bias decay
只对卷积层和全连接层中的weight参数做正则化,不对bias参数做正则化,防止过拟合。
Low-precision training
采用FP16进行训练,加快训练速度。
Experiments
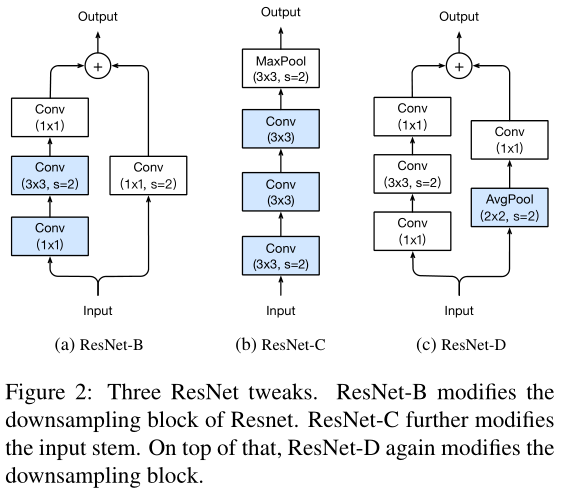
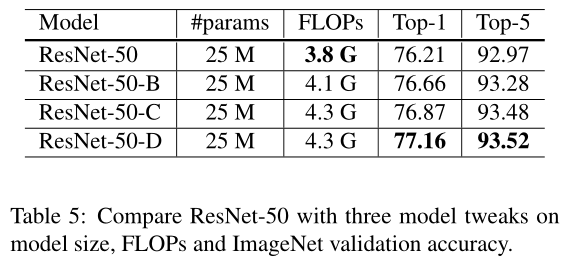
此外还可以尝试修改ResNet的结构、学习率衰减策略、标签平滑、知识蒸馏、Mixup