Motivation
细粒度任务中的对象通常共享较小的类间方差和较大的类内方差,以及多个对象范围和复杂的背景,从而导致更复杂的问题空间。
如果将此类数据进一步划分为子集进行训练,则由于可获得的数据量较少,每个生成的专家模型都更容易过度拟合。
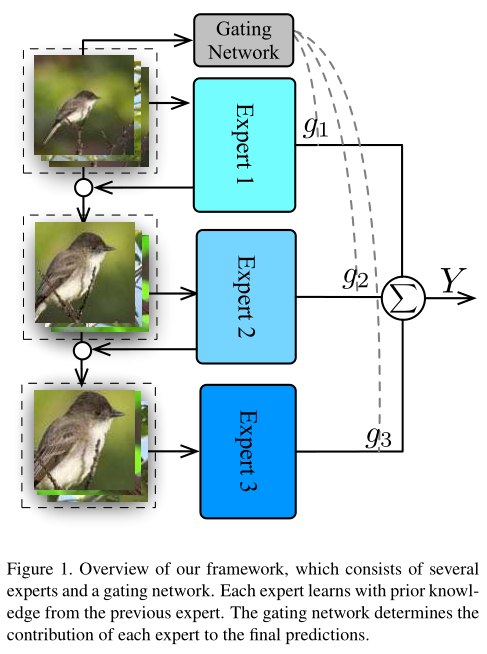
Methods
方法由多名专家和一个门控网络组成。
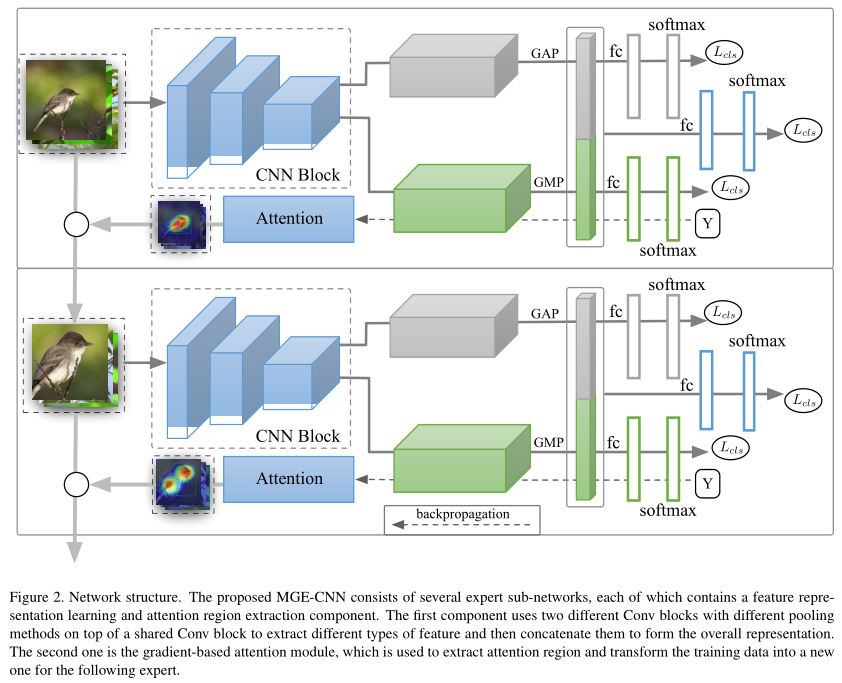
Experts for Fine-Grained Recognition
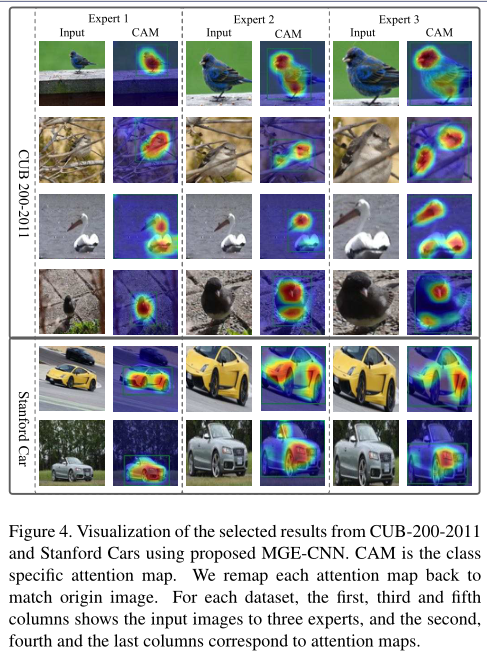
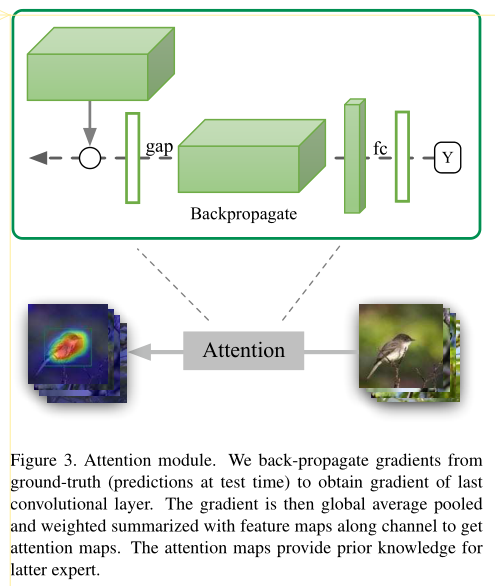
每一个专家生成基于CAM的Attention Map,找出更细致的关注点,裁剪图像作为输入送给下一个专家模型。
KL-Divergence based Penalizing Term
基于KL散度的惩罚项,鼓励不同专家关注不同的点,产生不同的结果。 \[ \begin{array}{c} D_{K L}\left(P^{t} \| P^{t+1}\right)=\sum_{x \in X^{t}} P^{t}(x) \log \left(\frac{P^{t}(x)}{P^{t+1}(x)}\right) \\ =\sum_{x \in X^{t}}\left(P^{t}(x) \log \left(P^{t}(x)\right)-P^{t}(x) \log \left(P^{t+1}(x)\right)\right) \end{array} \]
Mixture of Experts
\[ L=\sum_{t=1}^{T} L_{c l s}^{t}+\sum_{t=2}^{T} L_{K L}^{t}+L_{g a t e} \]
将不同专家结果通过Gate网络的输出权重融合,生成最终结果。 \[ \hat{y}_{i}=\sum_{t=1}^{T} g_{t} * \hat{y}_{i}^{t} \]
Experiments