Motivation
- 病理图像中细胞核分布广泛,形态上存在巨大差异
- 标注工作量大
- 自监督学习可以缓解数据量不足的问题,分为两个阶段
- 在大型无标注数据集上预训练网络模型
- 在特定小型有标注数据集上微调预训练模型
Methods
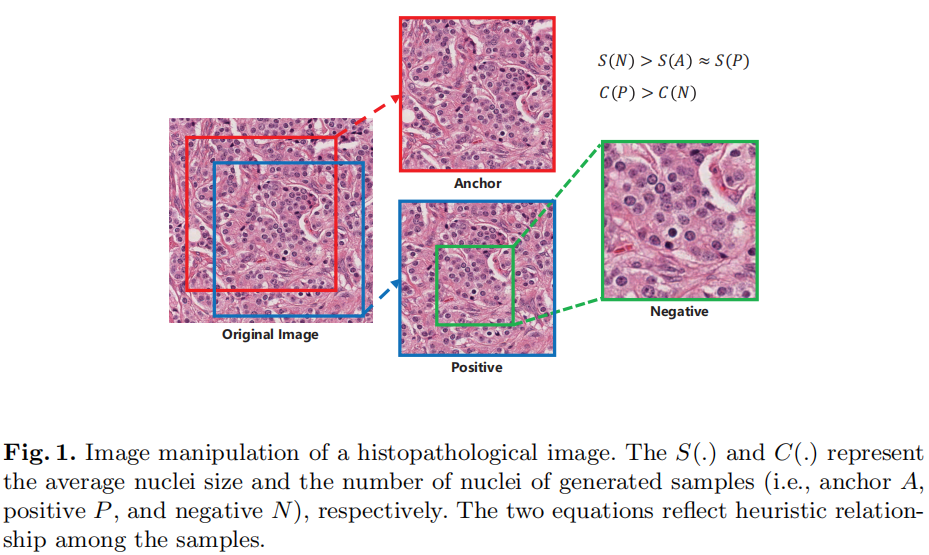
Image Manipulation
先通过锚点生成一个patch,再随机裁剪一个同样大小的patch,且核数量相近的作为正样本,再从正样本中裁剪出一小块作为负样本。
锚点,正样本和负样本构成标准的三元组数据,该数据用于自我监督学习中的代理任务。
Self-supervised Approach with Triplet Learning and Ranking
分为两部分:Triplet Learning和Ranking
下图中三个Encoder共享权重,得到的三个特征向量均为128-d
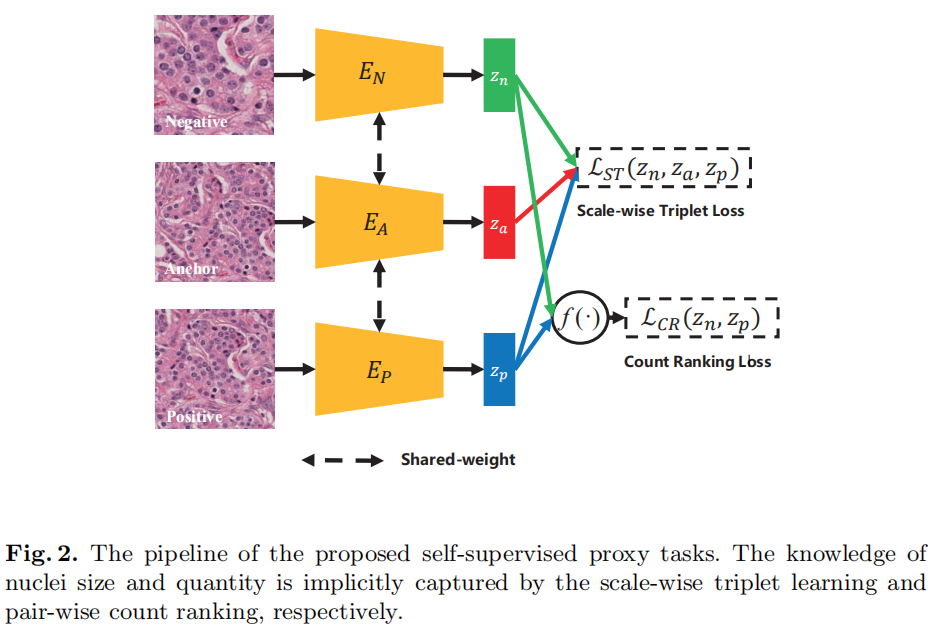
Scale-wise Triplet Learning
Anchor、正样本、负样本三者之间存在的scale和核数量不同,通过triplet learning学习三者之间的关系。 \[ \mathcal{L}_{S T}\left(z_{a}, z_{p}, z_{n}\right)=\sum \max \left(0, d\left(z_{a}, z_{p}\right)-d\left(z_{a}, z_{n}\right)+m_{1}\right) \]
Count Ranking
正样本比负样本存在更多的核数量,通过pair-wise count ranking loss强制网络识别包含更大核数量的样例。 \[ \mathcal{L}_{CR} = \sum{max(0, f(z_n)-f(z_p)+m_2)} \]
目标函数
\[ \mathcal{L} = \mathcal{L}_{ST} + \mathcal{L}_{CR} \]
Fine-tuning on Target Task
采用现有的单阶段核实例分割框架用于实例分割,主干网络采用ResNet-101,最终框架可以称为ResUNet-101。
将模型的Encoder通过上文提及的自监督方法进行预训练,然后加入随机初始化的Decoder,在目标任务上进行微调预训练模型。
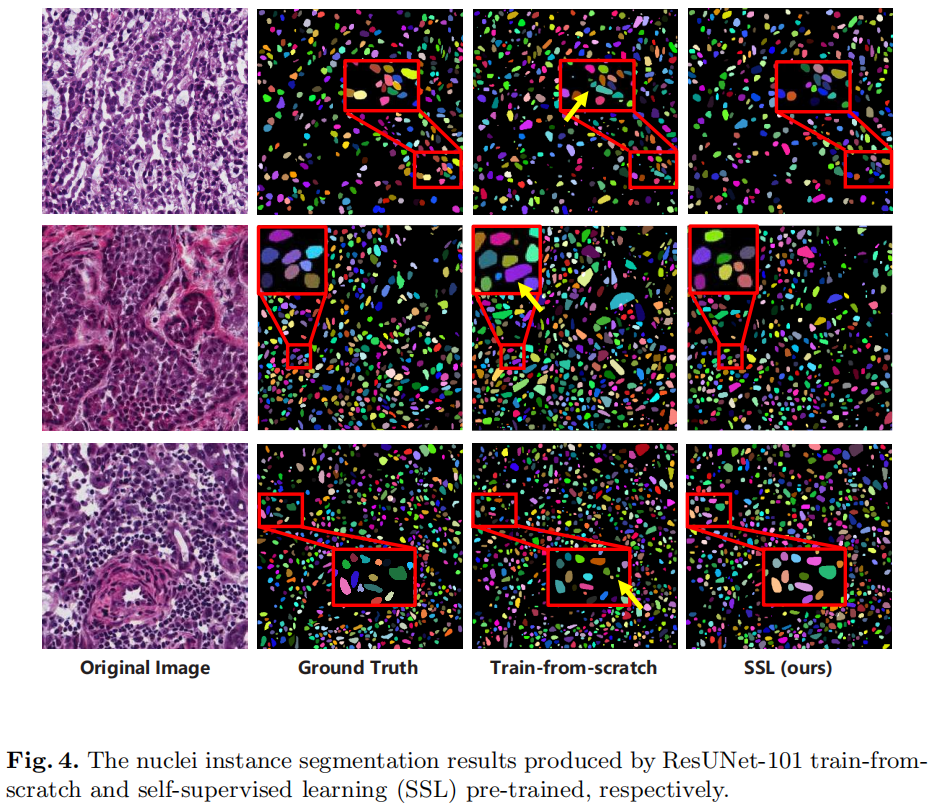
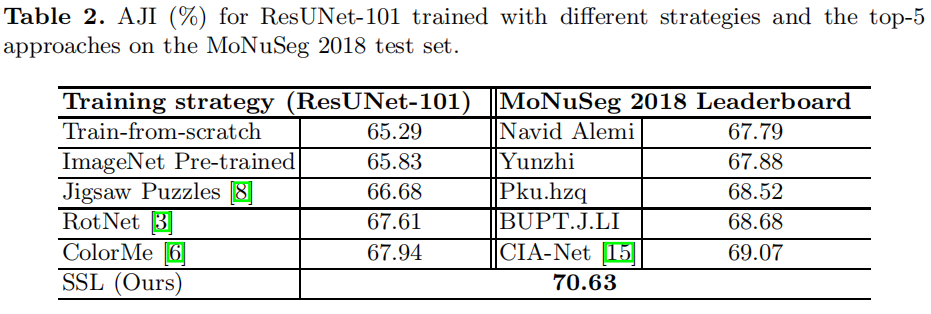
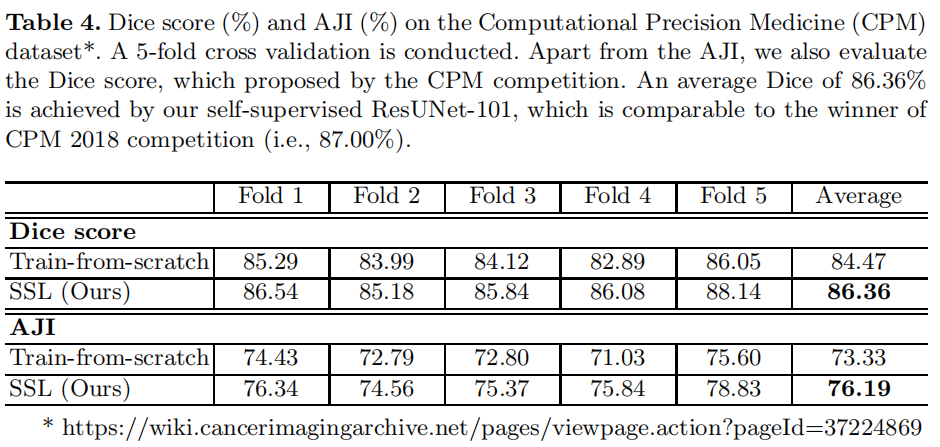
Experiments