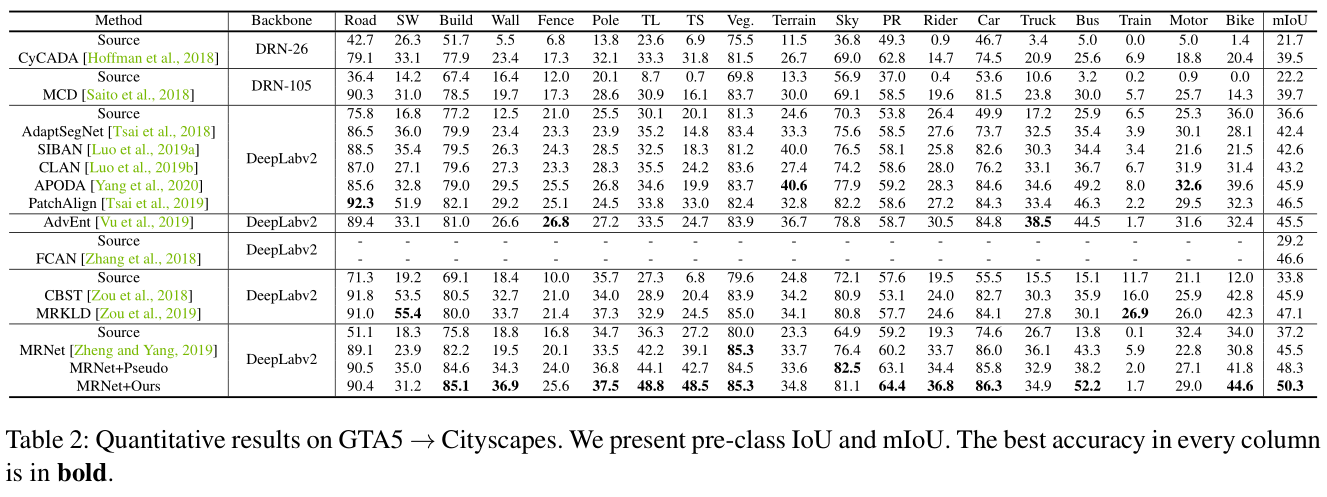
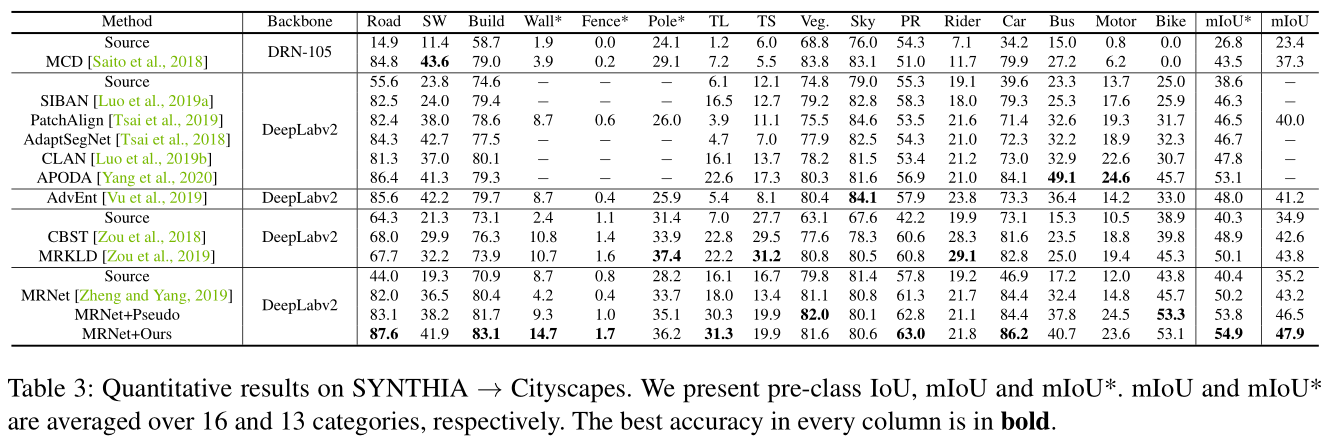
【详细讲解参考】利用Uncertainty修正Domain Adaptation中的伪标签
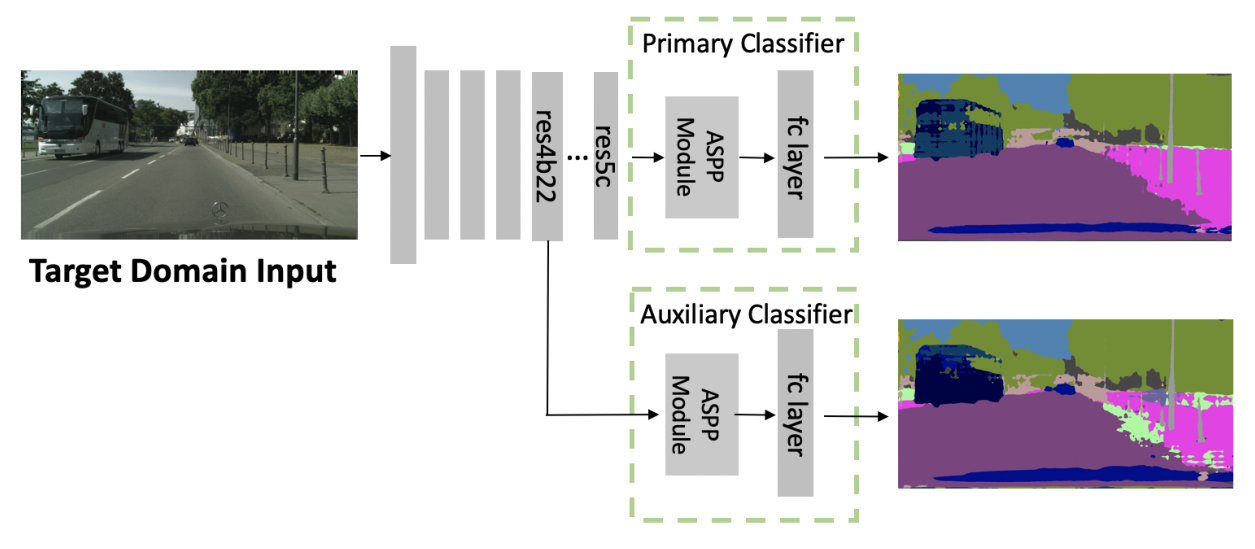
在分割模型中加入了辅助分类器(本来只是用来防止梯度消失的),结构如下图:有一个主分类器接在res5c后面,一个辅助分类器接在res4b22
观察到,伪标签错误的地方,往往是两个分类器预测不同结果的地方(Prediction Variance)
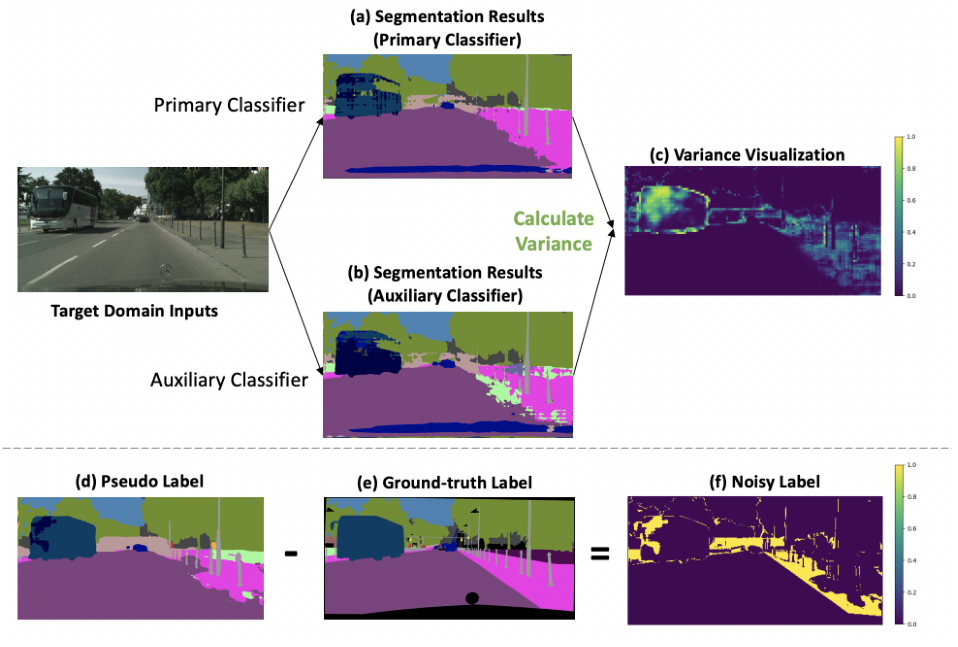
所以很自然的我们对于cross-entropy loss做了一个修正:其中\(D*{kl}\) 就是主分类器和辅助分类器预测结果的KL距离(也可以叫作Prediction Variance),如果差异大,则这个距离也就大,那么Lrect 对于这种不确定的样本,就不惩罚(因为pseudo label很可能是错的)。如果没有后面+\(D_{kl}\) 这一项,模型很懒,会趋向把所有pseudo label都说成是不确定的,那么Lrect就等于0了。为了避免这种情况,所以我们加了一个+\(D_{kl}\) 。
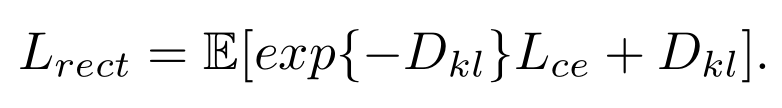
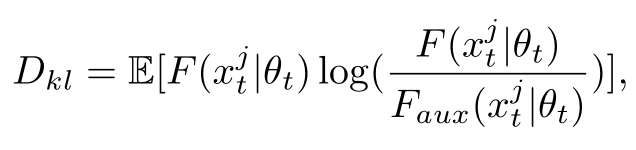
对于一些segmentation里面占得面积小的类别有奇效。因为传统方法按照confidence一刀切。往往数量小的类别(自行车Bike和骑行人Rider)这种类别吃亏,因为confidence score往往只有0.7,0.8,会被0.9的硬阈值卡掉。