Code: https://github.com/donnyyou/torchcv
Motivation
场景解析通常需要得到高分辨率且具有丰富语义特征的特征图,如利用空洞卷积和特征金字塔,但这些方法需要较多的计算量,不够有效。
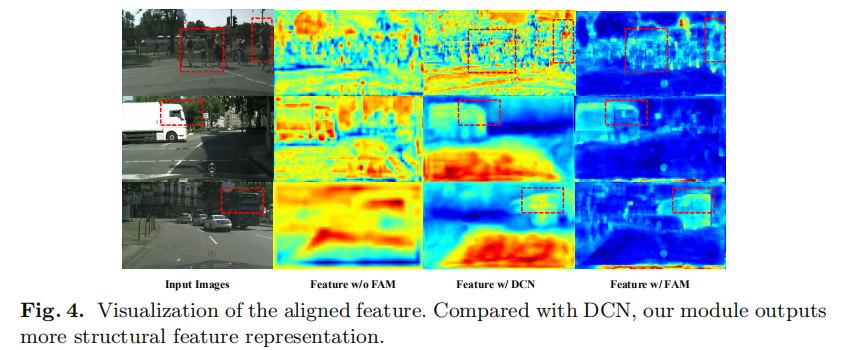
从利用光流对相邻视频帧进行运动对齐的方法受到启发,本文提出一种FAW(Flow Alignment Module)的方法,来学习相邻尺度特征图之间的语义流。和FPN结构融合在一起,实现了快速又精确的结果。
Methods
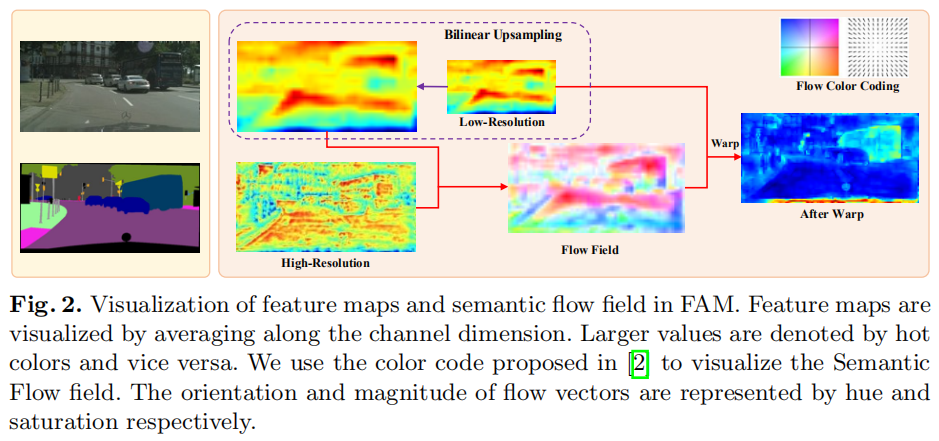
Flow Alignment Module
为了更灵活,更动态地对齐,光流法对于在视频处理任务中对齐两个相邻的视频帧特征非常有效且灵活。
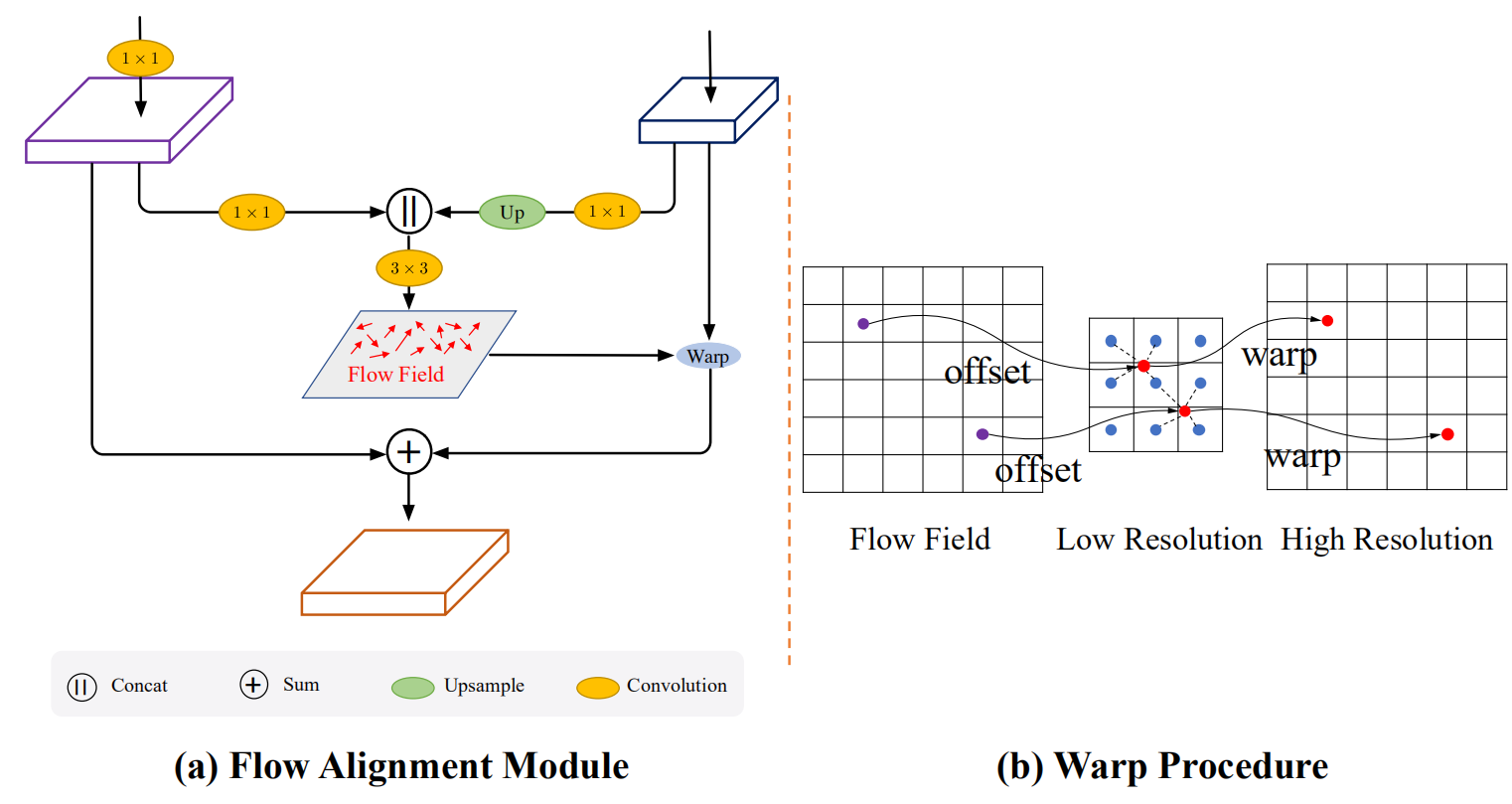
首先给出相邻两层特征图\(F_l\)和\(F_{l-1}\),首先将特征图\(F_l\)进行双线性插值上采样,得到的特征图与\(F_{l-1}\)相同尺寸。然后将两个特征图concat,再经过一个\(3 \times 3\)卷积,预测出语义流场。 \[
\Delta_{l-1}= conv_l (cat(F_l, F_{l-1}))
\] 由于输入特征与流场之间存在分辨率差距,因此将偏移量减半 \[
p_l = \frac{p_{l-1} + \Delta_{l-1}(p_{l-1})}{2}
\] 
Network Architectures
Backbone
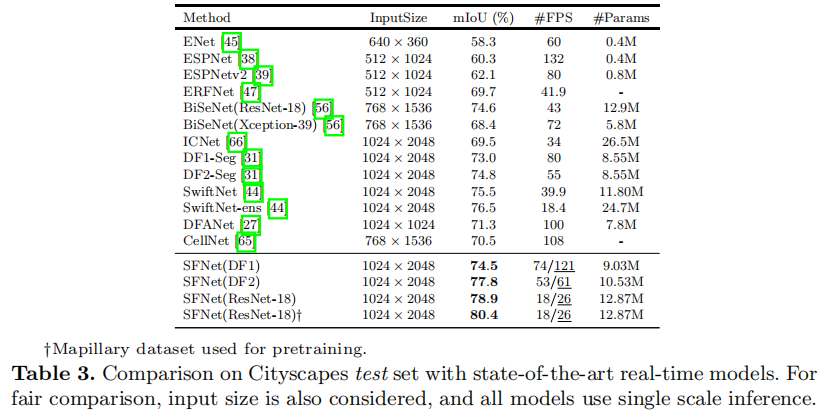
resnet系列、ShuffleNet V2、DF系列
Contextual Module
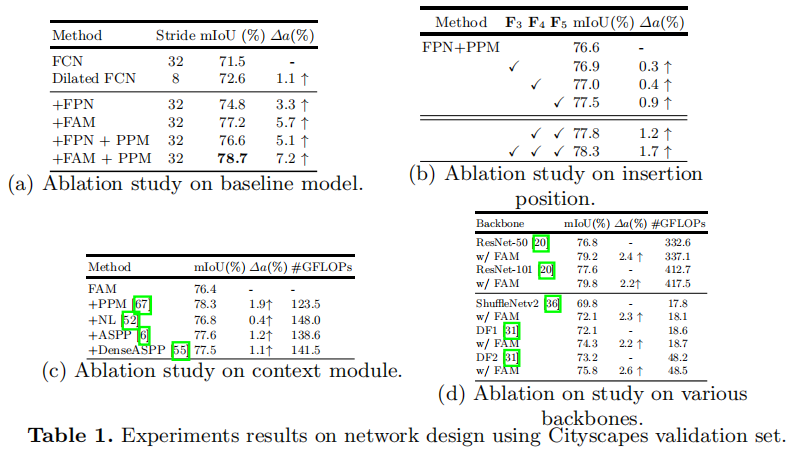
采用Pyramid Pooling Module(PPM)用于捕获长距离的上下文信息
Aligned FPN Decoder
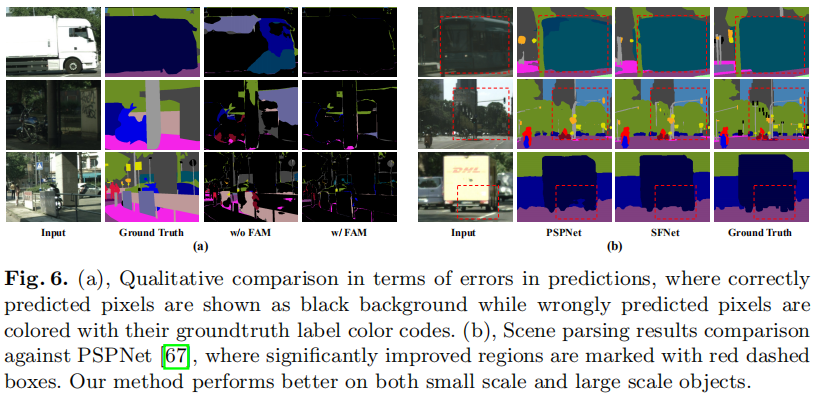
从Encoder中得到特征图,使用对齐的特征金字塔为最后一层的场景解析。使用FAM替换传统的双线性插值模块
Cascaded Deeply Supervised Learning
使用深度监督损失来监督中间输出,使得解码器更容易优化。
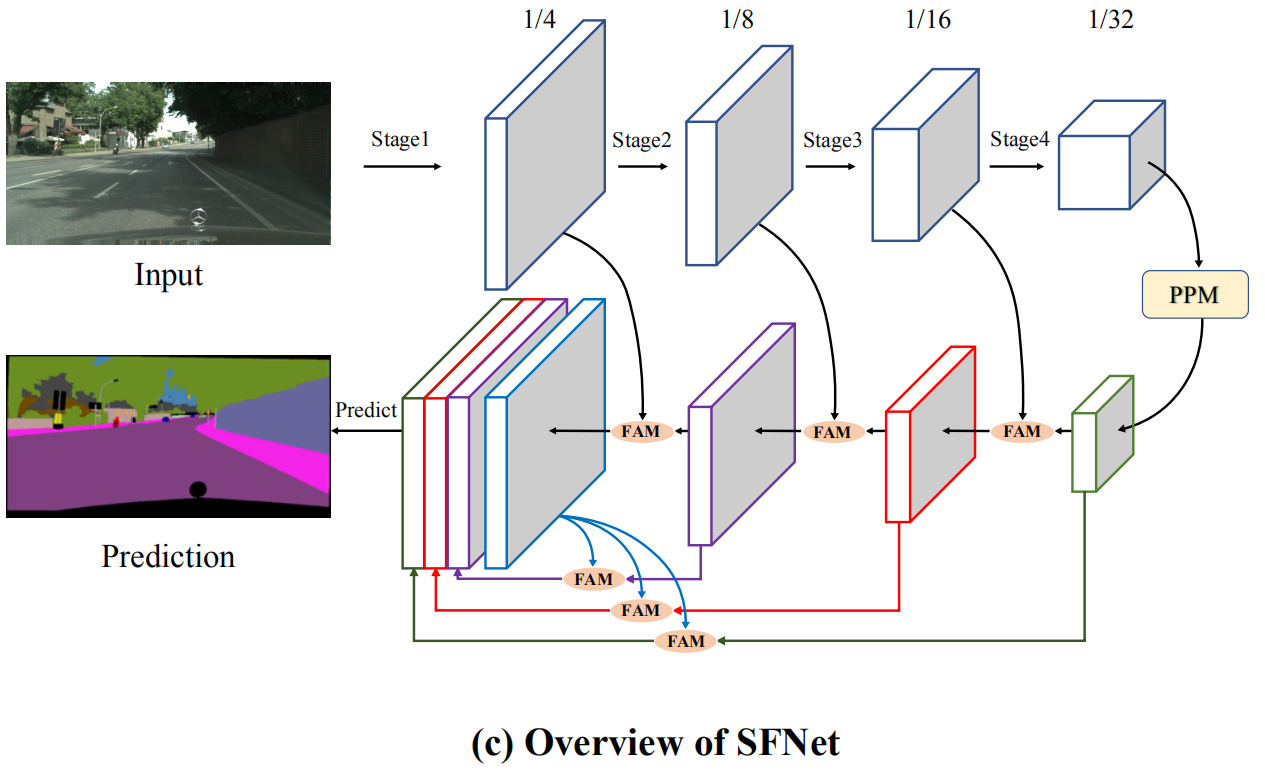
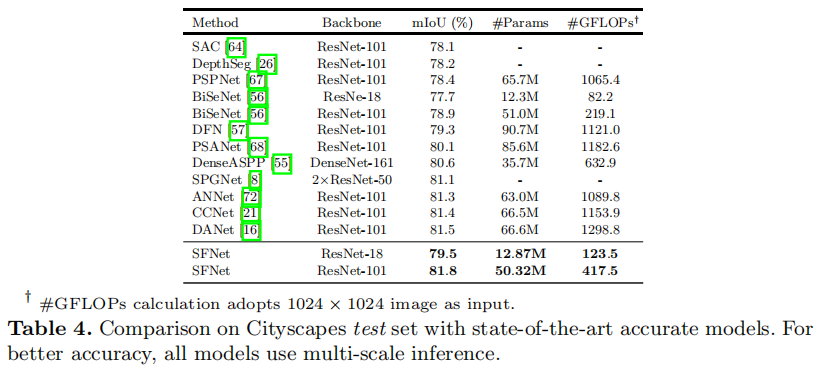
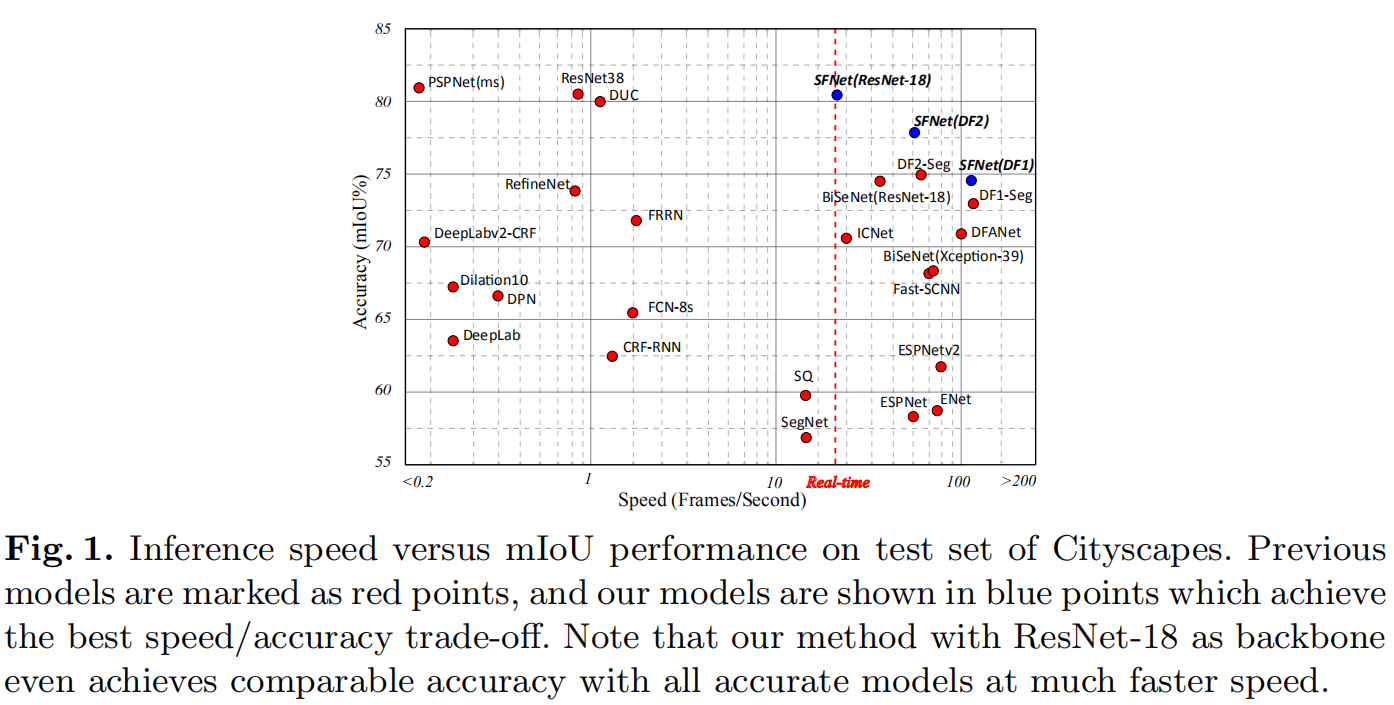
Experiments