Code: https://github.com/facebookresearch/moco
Pdf: https://arxiv.org/abs/1911.05722
Motivation
现有无监督算法构建动态字典,字典中的“键”从数据(图像或patch)采样,由encoder表示。无监督学习训练encoder来执行字典查找。一个被编码的“查询”应当尽可能与匹配的键相近,和其他的疏远。学习过程被公式化为最小化对比损失。
从这个角度看,本文构建的字典的特征:(1)大;(2)随着训练过程中的演变而一致。直观上,较大的字典可能更好地采样底层连续的、高维的视觉空间,而字典中的键应该由相同或相似的编码器表示,以便它们与查询的比较是一致的。 但是,使用对比损失的现有方法可能会在这两个方面之一受到限制。
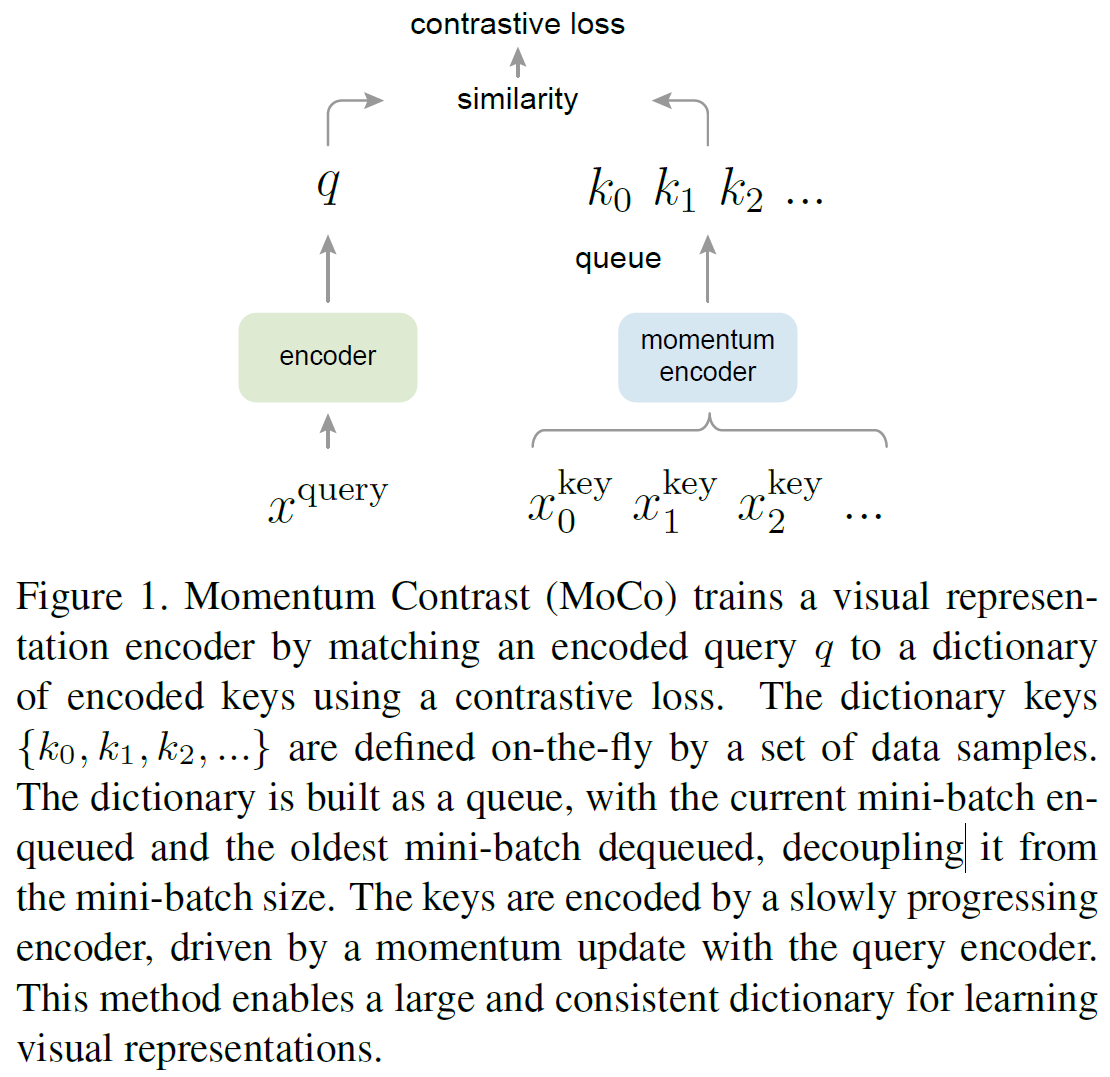
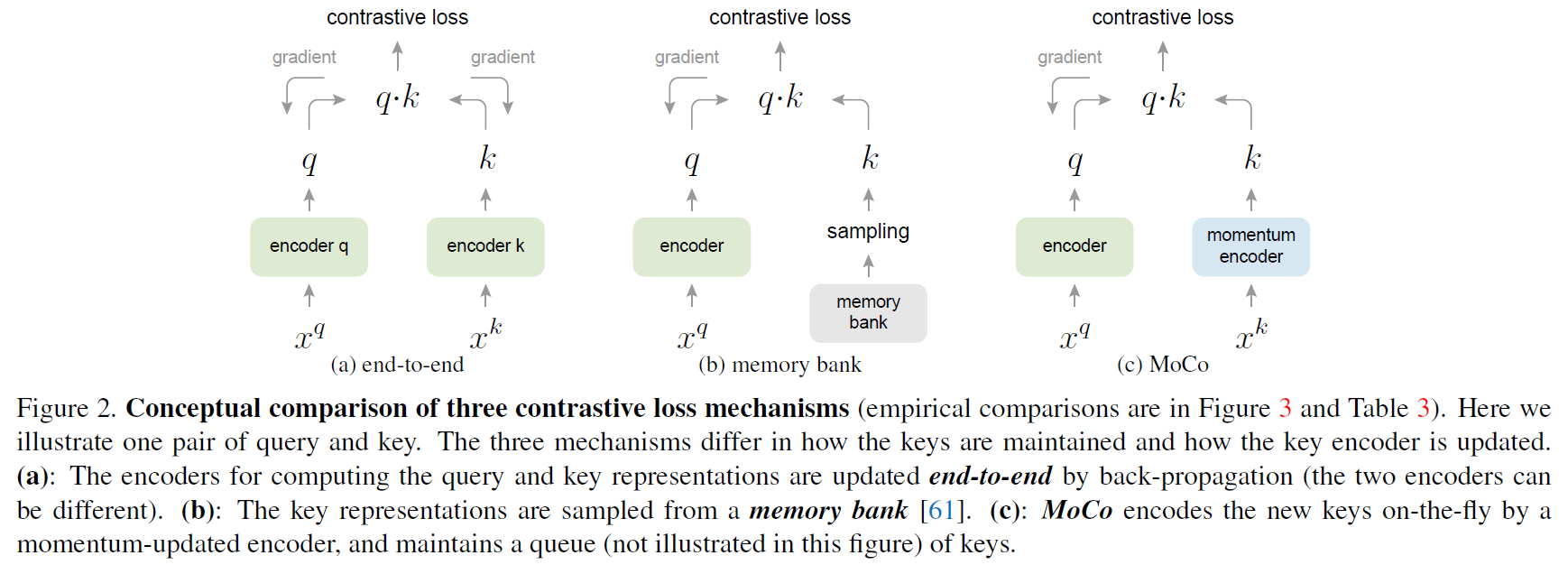
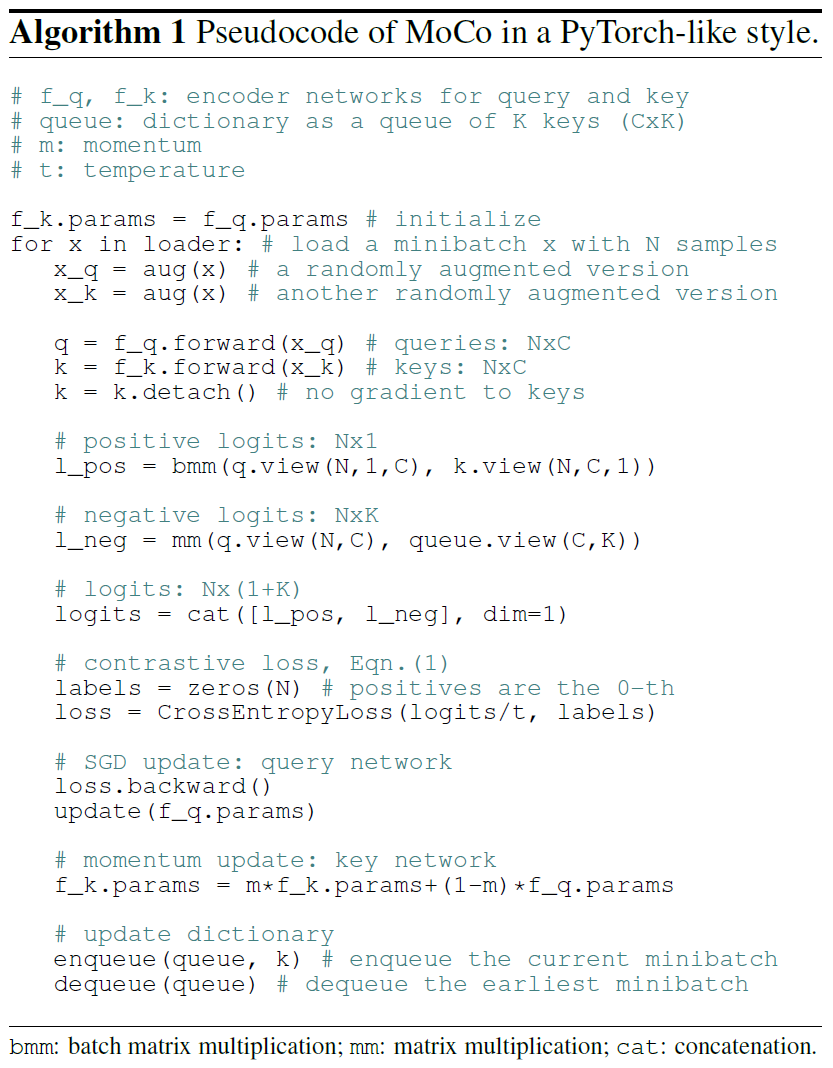
本文提出的方法Momentum Contrast(MoCo)作为一种基于对比损失的构建大型一致性词典的无监督学习算法。将字典维护为一个数据样本队列,当前mini-batch入队,最旧的出队。采用一个slowly progressing key encoder,实现为基于动量移动平均值的查询编码器,以保持一致性。
Methods
Contrastive Learning as Dictionary Lookup
对比学习可以看做是为了字典查找任务训练一个编码器。
定义查询\(q\)和一组样本\(\{k_0, k_1, k_2,...\}\)为字典的键,假设有一个\(q\)匹配的键(\(k_+\))。对比损失是为一个公式,当\(q\)和\(k_+\)相近时计算值较低,反之较高。通过点积测量相似性,被称为InfoNCE: \[ \mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)} \]
Momentum Contrast
Dictionary as a queue
方法的核心是将字典维护成数据样本队列。本文的字典大小可以远大于典型的mini-batch大小,可以灵活独立设置为超参数。当前mini-batch加入到字典中,队列中最旧的mini-batch被移除。字典总是代表着所有数据的一个抽样子集。
Momentum update
如果想获取到较好的表示学习效果,那么负样本一定要足够的大,也就是要构建一个足够大的字典,让网络能够充分学习到正负样本的区别。但是此时就面临一个问题,收到mini-batch的限制,字典无法做到很大,要不然性能消耗会爆炸。
由于字典中的并不是同一批次的,那么对应encoder肯定也是不同的了,如何更新对应点编码器呢?所以MoCo在这里又给出一条约束,就是地点变化要足有平滑连续,不然key1是由旧的Encoder1编码得到,如果Encoder1和新的Encoder2相差较大,那么key1对应的损失是无法给Encoder提供参考信息的。 \[
\theta_k \larr m \theta_k + (1-m)\theta_q
\] 
Experiments