引言
概述
本文主要介绍ResNet的变体:ResNeSt。
目前代码已经提供PyTorch和MXNet两个版本。
【Code】https://github.com/zhanghang1989/ResNeSt
性能显著提升,参数量并没有显著增加。
借鉴了:Multi-path 和 Feature-map Attention思想。
其中:
- GoogleNet 采用了Multi-path机制,其中每个网络块均由不同的卷积kernels组成。
- ResNeXt在ResNet bottle模块中采用组卷积,将multi-path结构转换为统一操作。
- SE-Net 通过自适应地重新校准通道特征响应来引入通道注意力(channel-attention)机制。
- SK-Net 通过两个网络分支引入特征图注意力(feature-map attention)。
主要贡献
- 在ResNet的基础上进行了修改,结合了feature-map split attention机制。
- 在图像分类和迁移学习上都有很大提升,可以作为这些领域的benchmark。
方法
概述
ResNeSt主要引入了Split-Attention block,由feature-map group和split attention operation组成。
SE-Net、SK-Net、ResNeSt的结构图如下:
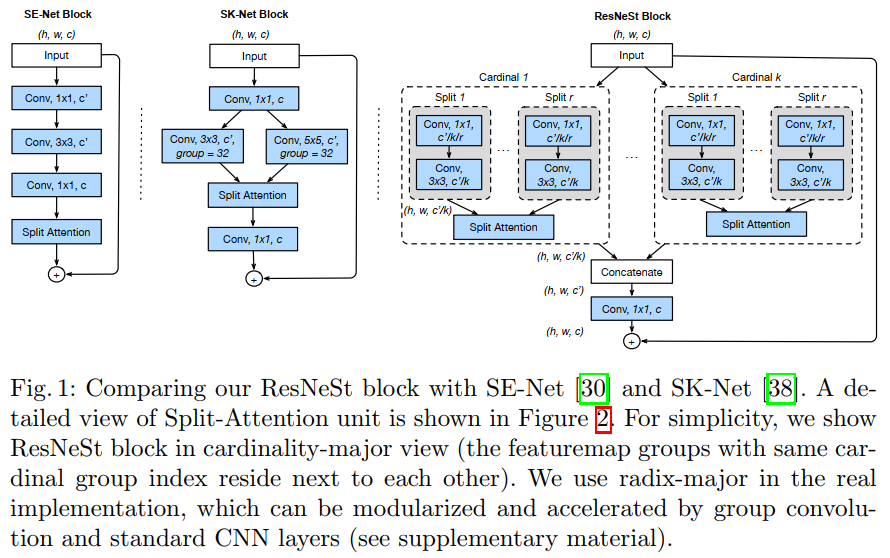
其中Split Attention的结构如下:
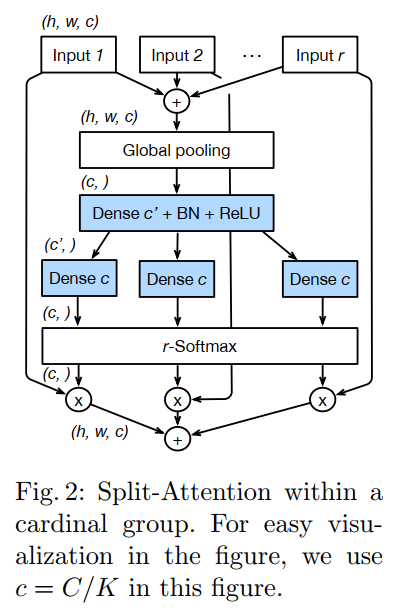
从图1和图2可知,都有split的影子。比如图1中的 \(K(k)\) 和图2中的 \(R(r)\) 都是超参数,也就是共计 \(G = K*R\) 组。
Feature-map Group
如图 2,仿照ResNeXt block,将特征分为多个组,特征组的数量由超参数K控制。
每一个组由分成多个cardinal组,数量由R控制。
因此所有组的数量为\(G=K\times R\)。
每个小组应用一系列变化\(\{F_1, F2, ..., F_G\}\),每个组的中间表示使用\(U_i=F_i(X)\),其中\(i \in \{1,2,...,G\}\)。
Split Attention in Cardinal Groups
受SENet和SKNet启发,每一个cardinal组的表达通过像素级相加的方式融合起来,公式表示为\(\hat{U}^k=\sum_{j=R(k-1)+1}^{Rk}{U_j}\),其中\(\hat{U}^k \in R^{H \times H \times C/K}, k \in 1,2,...,K\)。
通过空间维度的全局平均池化实现聚合通道维度的全局上下文信息,第c个组件具体公式如下: \[ s_c^k=\frac{1}{H \times W}\sum_{i-1}^{H}\sum_{j=1}^{W}{\hat{U}_c^k(i,j)} \] cardinal组表示的加权融合使用通道维度soft注意力实现,其中每个channel的特征图使用加权组合产生。 \[ V_{c}^{k}=\sum_{i=1}^{R} a_{i}^{k}(c) U_{R(k-1)+i} \]
\[ a_{i}^{k}(c)=\left\{\begin{array}{ll} \frac{\exp \left(\mathcal{G}_{i}^{c}\left(s^{k}\right)\right)}{\sum_{j=0}^{R} \exp \left(\mathcal{G}_{j}^{c}\left(s^{k}\right)\right)} & \text { if } R>1 \\ \frac{1}{1+\exp \left(-\mathcal{G}_{i}^{c}\left(s^{k}\right)\right)} & \text { if } R=1 \end{array}\right. \]
ResNeSt Block
最终结果通过short cut连接:\(Y = V+X\)
当特征图大小不匹配时加入相应的变换:\(Y=V+T(X)\),\(T\)可以使用strided convolution或combined convolution-with-pooling。
Network Tweaks
Average Downsampling
对于某些要求空间信息的拓展任务来说保存空间信息使必要的。在此之前,ResNet通过带有stride的\(3 \times 3\)来实现降采样,但是这样对于边界的处理需要采用padding操作。而在本文中直接使用\(3 \times 3\)平均池化操作。
Tweaks from ResNet-D
- 将原始的\(7 \times 7\)卷积操作替换成3个\(3 \times 3\)的卷积操作,他们具有相同的感受野,计算量也较为相似。
- 在shortcut中\(1 \times 1\)卷积层前加入\(2 \times 2\)平均池化。
训练策略
这个对大家目前的工作应该具有很大的参考价值(涨点tricks)。
- Large Mini-batch Distributed Training
- Label Smoothing
- Auto Augmentation
- Mixup Training
- Large Crop Size
- Regularization
实验结果
图像分类
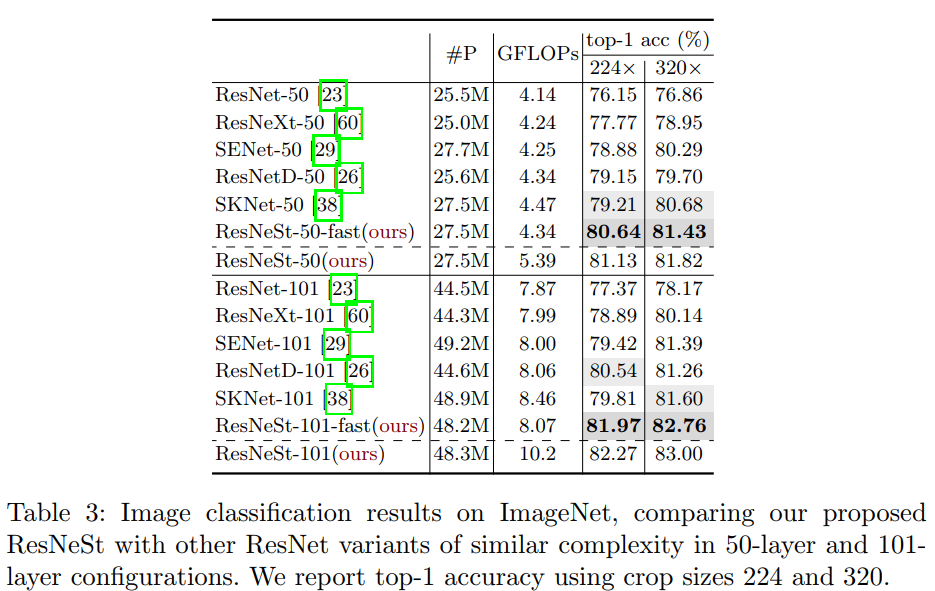
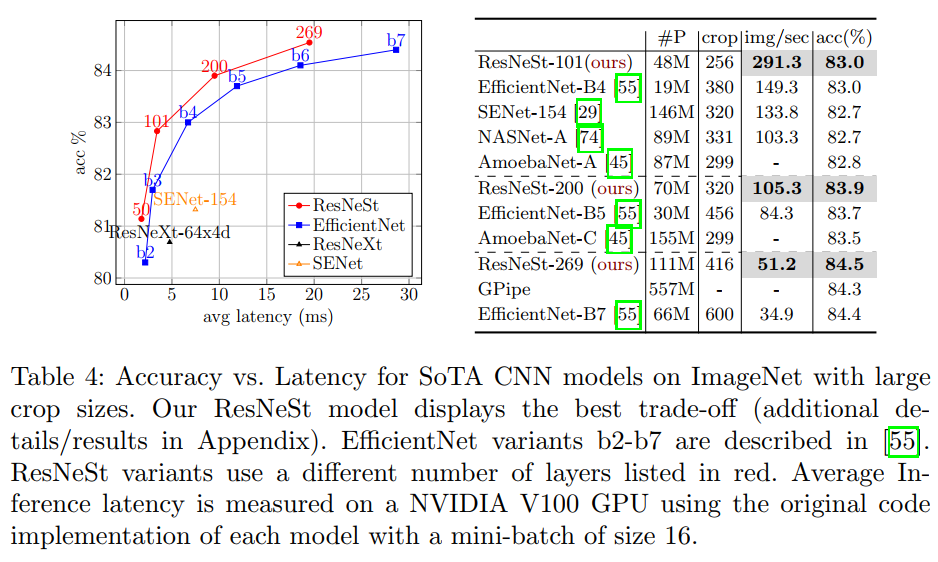
目标检测

实例分割

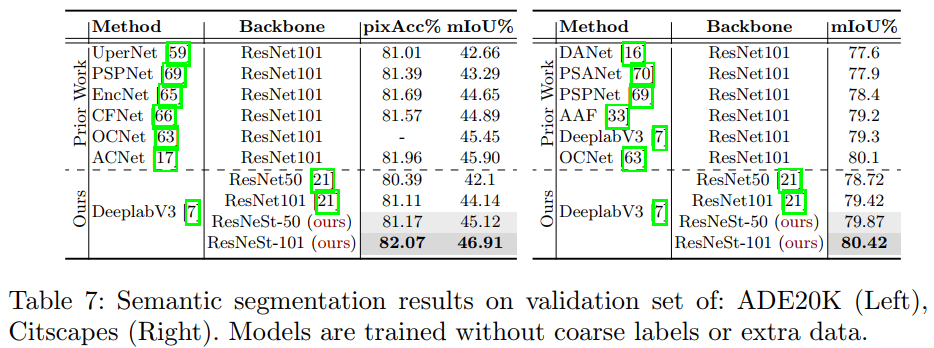
语义分割
作者的次要结论
- depth-wise convolution is not optimal for training and inference efficiency on GPU,
- model accuracy get saturated on ImageNet with a fixed input image size,
- increasing input image size can get better accuracy and FLOPS trade-off.
- bicubic upsampling strategy is needed for large crop-size (≥ 320).
作者解答
这里的attention和sknet挺像
问题来自知乎
1). 我们相当于把 SKNet 的思想做到 ResNeXt 的 group 里更有效,而且相对于多分支的 SKNet 更模块化,易于优化。
2). 这篇 paper 其实并不是一个什么开创性的工作,感觉大家有点过高期待了,只是几个小伙伴在繁忙工作中抽出3个多星期的时间一起赶出来的,为了全面提高 gluoncv 项目里的所有模型的性能,最简单的方法就是提高 backbone。仅此而已。