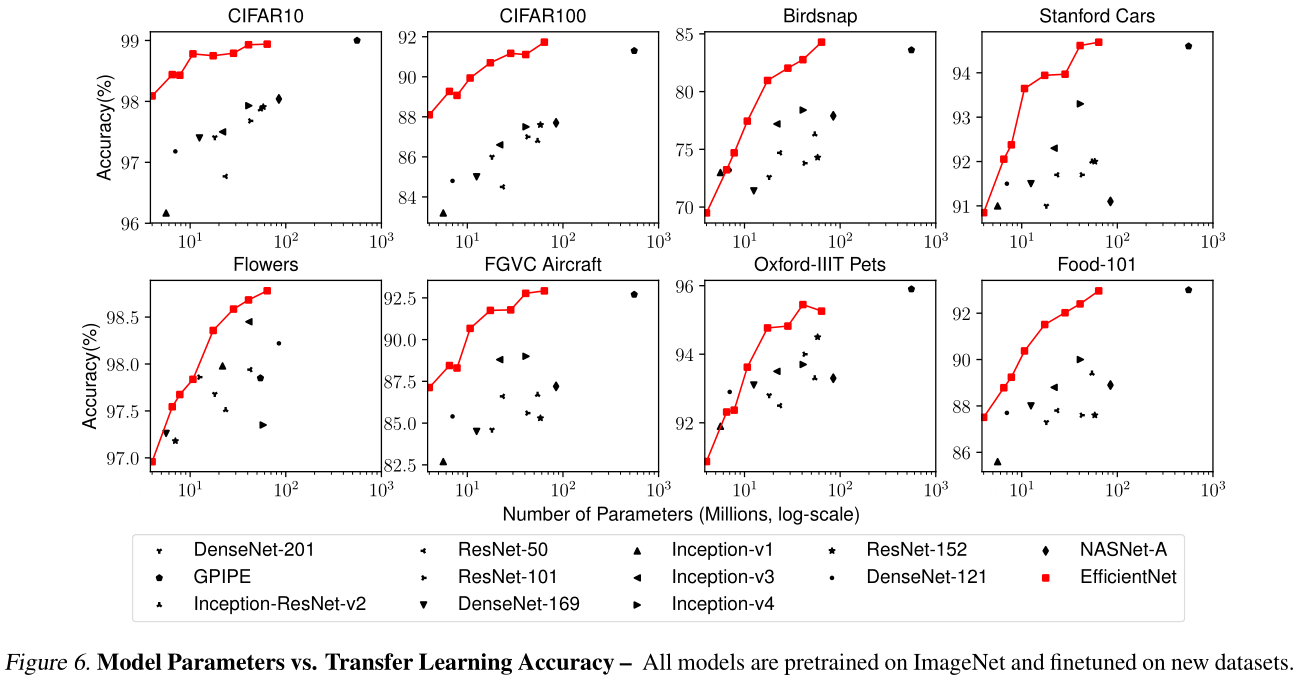
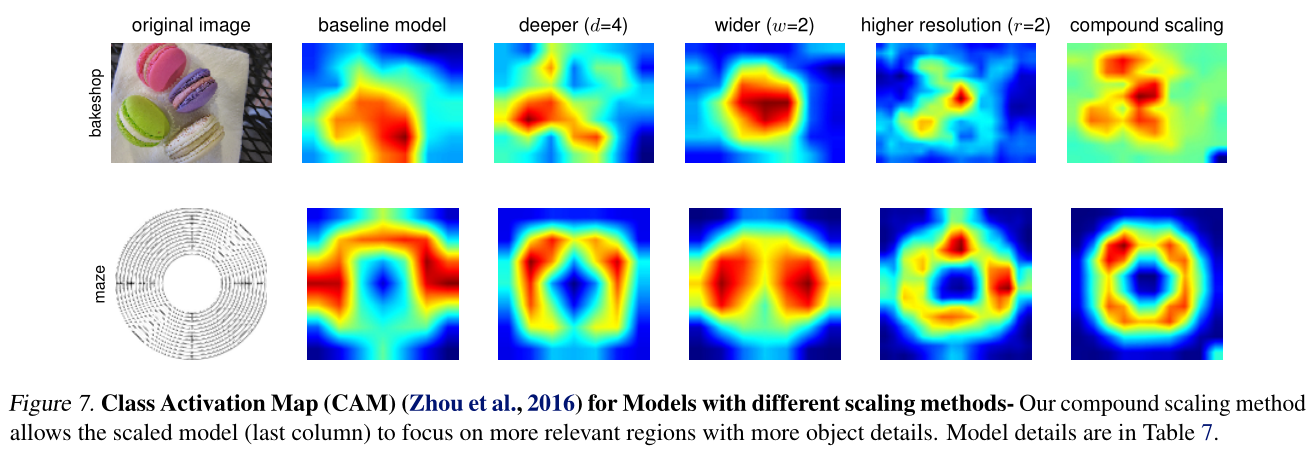
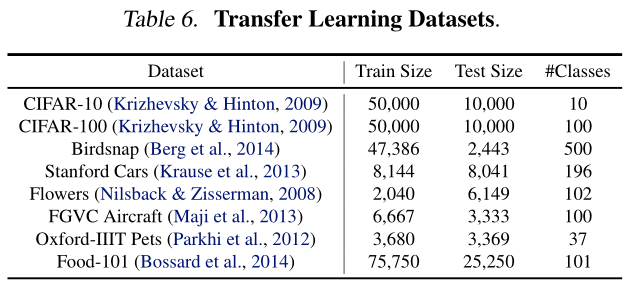
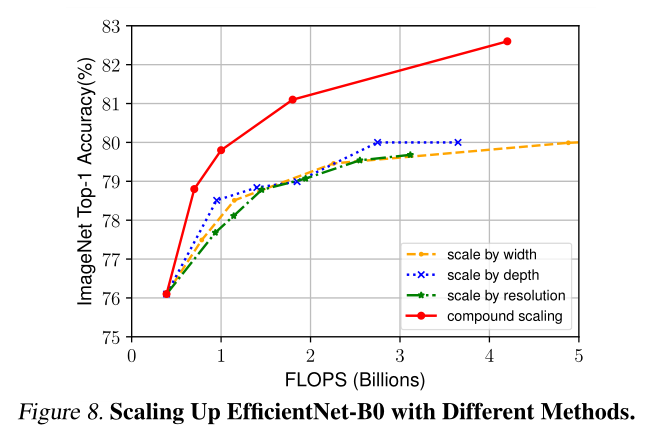
Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
Motivation
- 系统研究了缩放模型,发现平衡好网络的深度、宽度和输入数据的分辨率可以带来更好的性能。
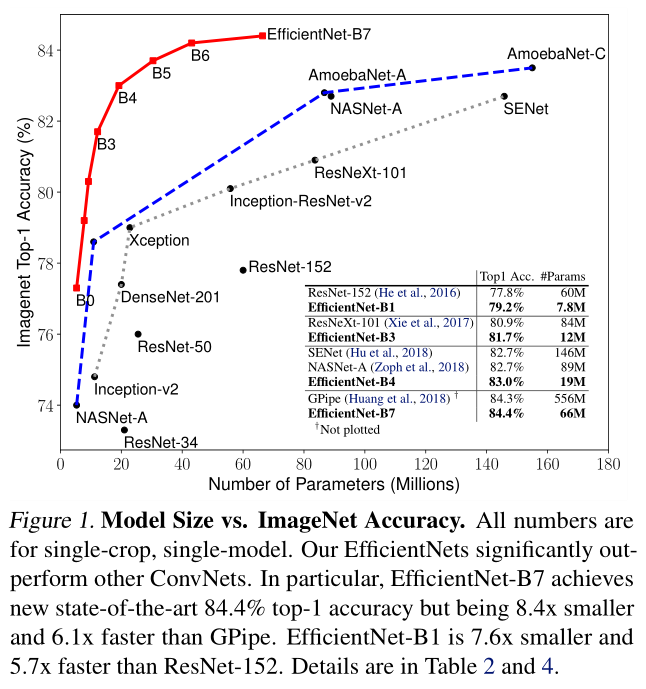
- 使用网络结构搜索设计了新的baseline网络,并扩展获得EfficientNet,比之前的卷积网络有更好的准确性和效率。
Methods
Problem Formulation
定义普通卷积网络为:
\[ \mathcal{N}=\bigodot_{i=1 \ldots s} \mathcal{F}_{i}^{L_{i}}\left(X_{\left\langle H_{i}, W_{i}, C_{i}\right\rangle}\right) \]
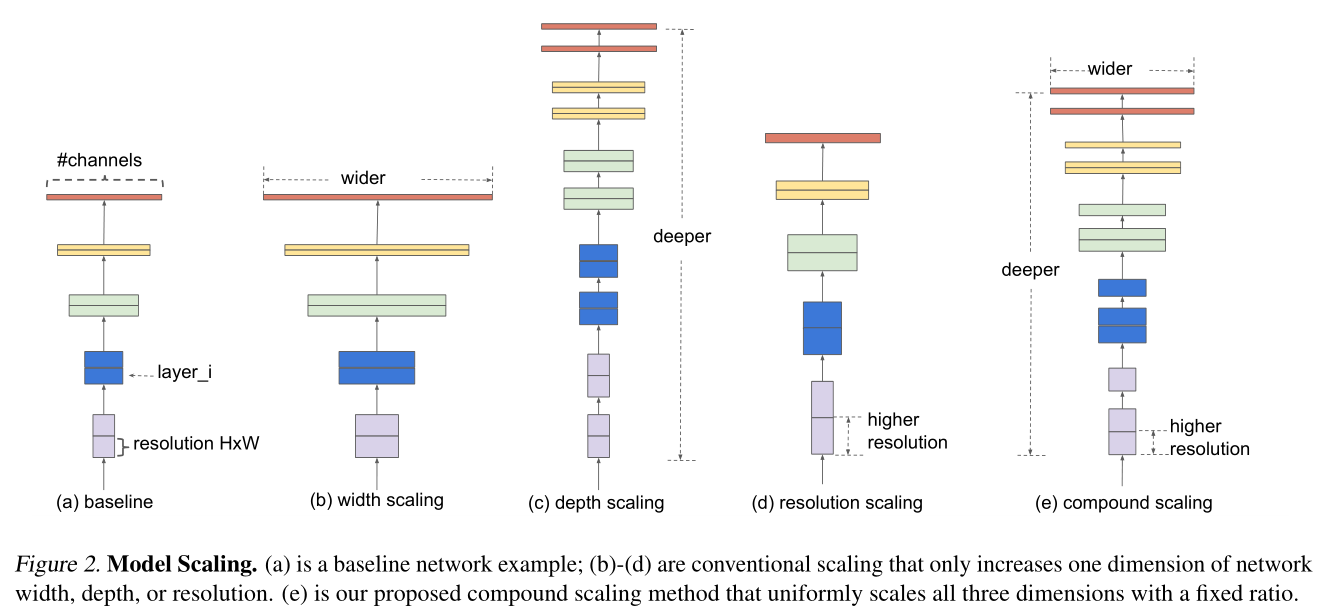
为了进一步减小设计空间,限制所有层必须以恒定的比例均匀缩放。本文的目标是在任何给定的资源约束条件下最大化模型准确性,这可以表述为优化问题:
\[ \begin{array}{ll} \max _{d, w, r} & \text {Accuracy}(\mathcal{N}(d, w, r)) \\ \text {s.t.} & \mathcal{N}(d, w, r)=\bigodot_{i=1 \ldots s} \hat{\mathcal{F}}_{i}^{d \cdot \hat{L}_{i}}\left(X_{\left\langle r \cdot \hat{H}_{i}, r \cdot \hat{W}_{i}, w \cdot \hat{C}_{i}\right\rangle}\right) \\ & \operatorname{Memory}(\mathcal{N}) \leq \text { target_memory } \\ & \operatorname{FLOPS}(\mathcal{N}) \leq \text { target_flops } \end{array} \]
Scaling Dimensions
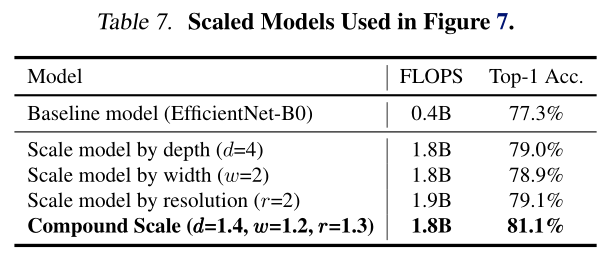
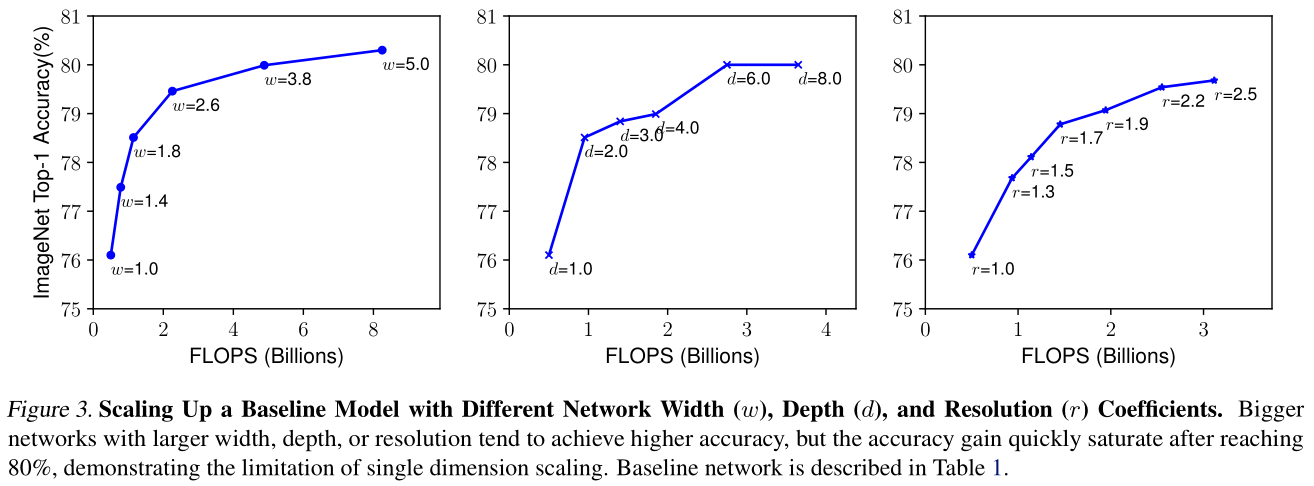
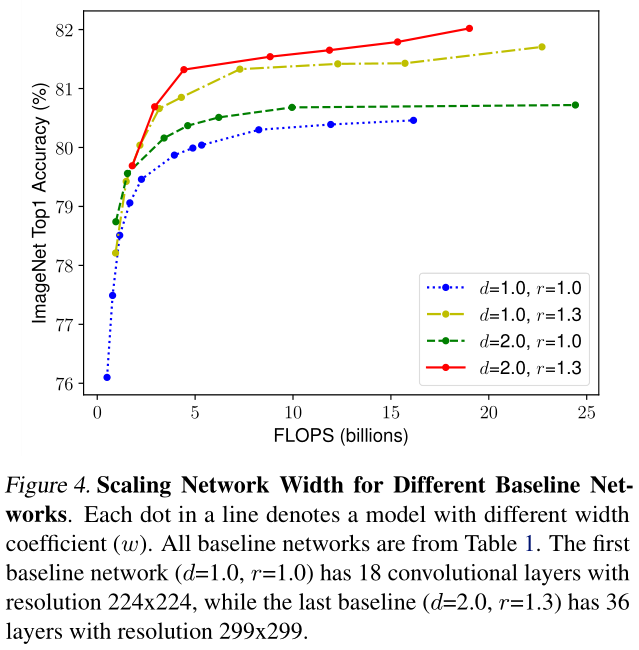
经分析,增大网络的宽度、深度和分辨率都可以给网络带来提升,但随着增大其增益逐渐减小。(如:ResNet-1000的准确度和ResNet-101的准确率相近)
观察
- 扩大网络宽度,深度或分辨率的任何维度都可以提高准确性,但是对于较大的模型,准确性的增益会降低。
- 为了追求更好的准确性和效率,在ConvNet扩展过程中平衡网络宽度,深度和分辨率的所有维度至关重要。
Compound Scaling
对于更高分辨率的图像,应该增加网络深度,以使较大的接收场可以帮助捕获相似的特征,这些特征在较大的图像中包括更多的像素。
需要协调和平衡不同的缩放比例,而不是常规的一维缩放比例。
在本文中,提出了一种新的复合缩放方法,该方法使用复合系数\(\phi\)原则上均匀地缩放网络的宽度,深度和分辨率。
\[ depth: d = \alpha^\phi \\ width: w = \beta^\phi \\ resolution: r = \gamma^\phi \\ s.t. \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2, \alpha \geq 1, \beta \geq 1, \gamma \geq 1 \]
EfficientNet Architecture
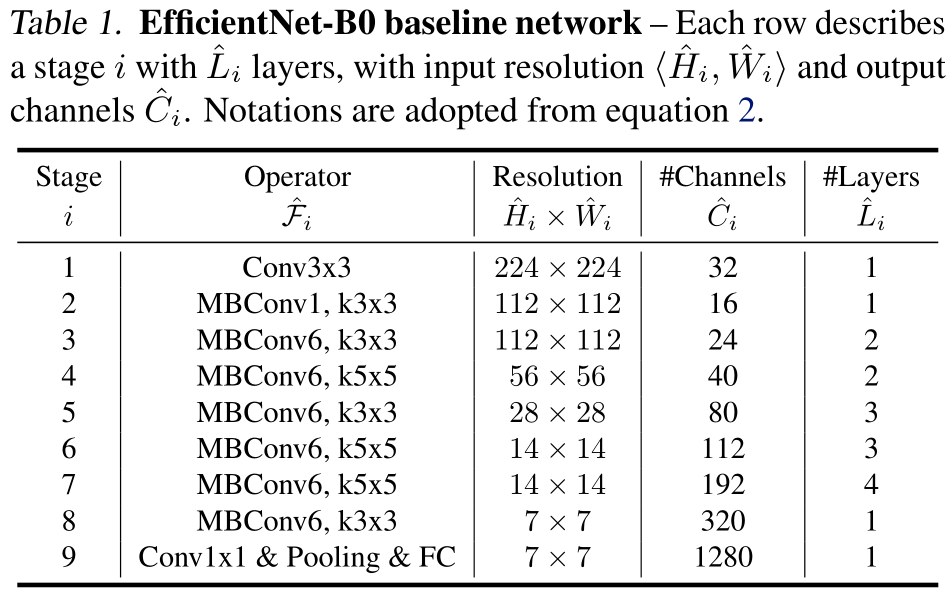
从基线EfficientNet-B0开始,我们应用复合缩放方法通过两个步骤对其进行扩展:
- 将\(\phi = 1\),如果资源的两倍空间可用,则通过小网格搜索\(\alpha,\beta,\gamma\)。发现最好的结果为EfficientNet-B0,\(\alpha=1.2,\beta=1.1,\gamma=1.15\),其中\(\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\)。
- 固定\(\alpha,\beta,\gamma\),缩放不同的\(\phi\),得到EfficientNetB1-B7。
Experiments