Code: https://github.com/tensorflow/models/tree/master/research/deeplab
Motivation
在语义分割任务中,spatial pyramid pooling module(SPP)可以捕获更多尺度信息,encoder-decoder结构可以更好恢复物体的边缘信息。
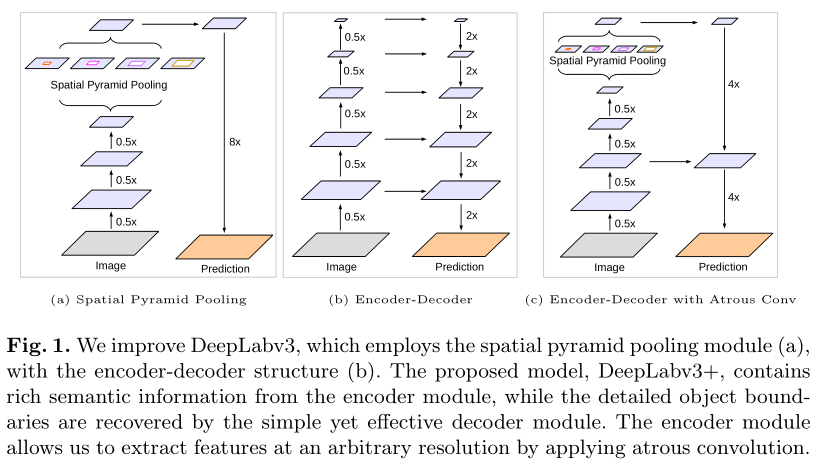
将DeepLab v3作为Encoder,添加新的Decoder,得到DeepLab v3+
Methods
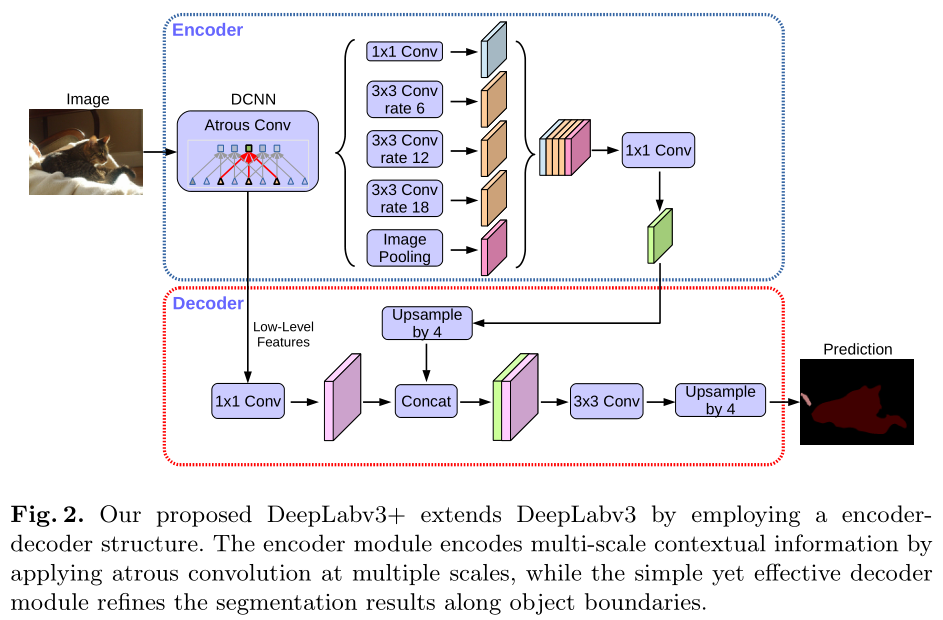
Encoder-Decoder with Atrous Convolution
Encoder-Decoder with Atrous Convolution
\[ y[i]=\sum_{k=1}^{K}{x[i+r\cdot k]w[k]} \]
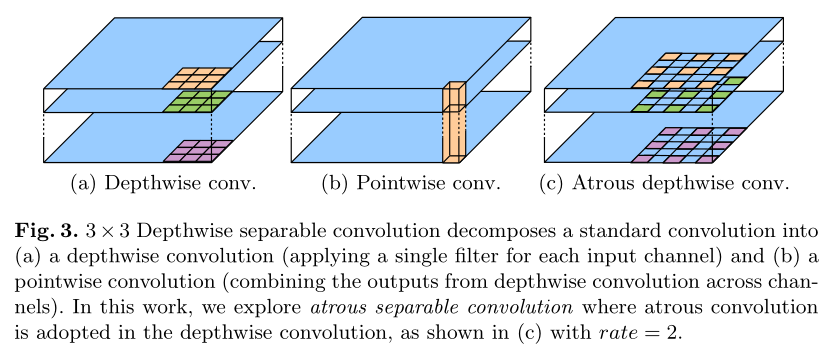
Depthwise separable convolution
将卷积替换为空洞可分离卷积,在保持性能的同时,降低模型的计算复杂度。
Depthwise separable convolution = depthwise convolution + pointwise convolution
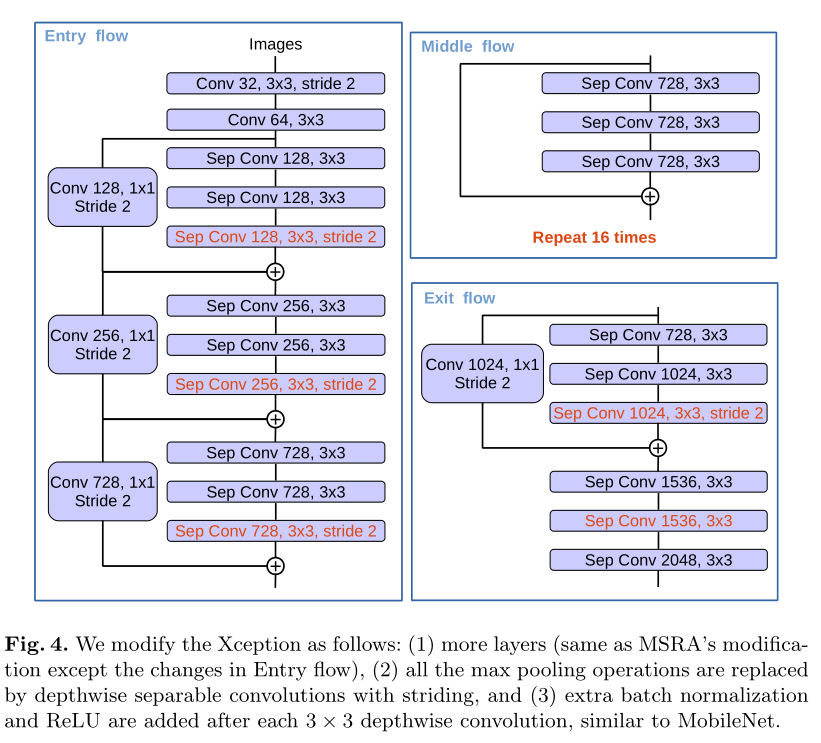
Modified Aligned Xception
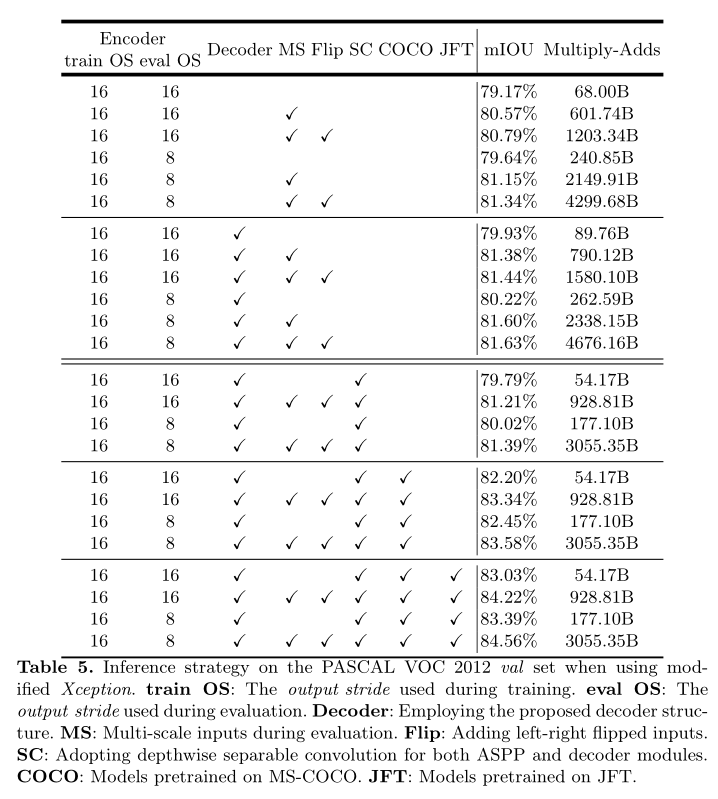
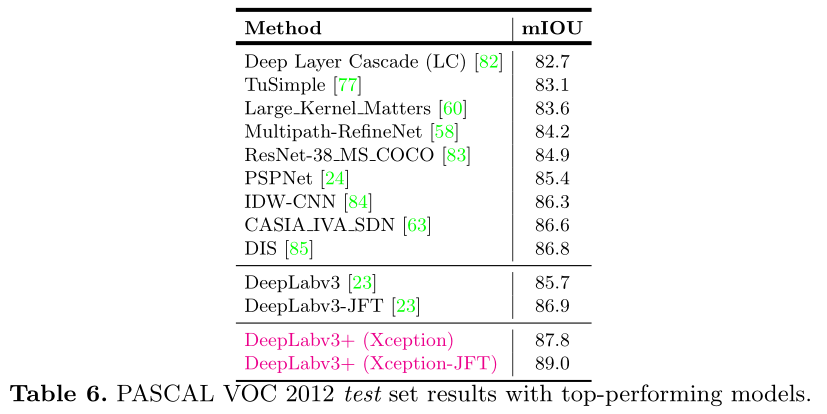
Experiments