Code: https://github.com/google-research/mixmatch
Motivation
深度学习的成功多半取决于大量的数据。
例如医疗数据中,很多数据是用非常昂贵的设备采集的,需要通过多名专家共同标注,非常耗时,而且存在隐私问题。
半监督学习(SSL)试图利用无标注的数据来减轻对有标数据的需求。很多SSL方法针对无标注数据增加损失项来使得模型很好的泛化到未见数据上。损失项可分为三类:熵最小化,一致性正则化和一般正则化。
本文贡献
- 实验证明MixMatch取得了state-of-the-art成果
- 消融实验证明MixMatch将每个模块加和效果最好
- MixMatch对于隐私学习很有效
Methods

MixMatch的损失定义如下: \[ X^{'},U^{'}=MixMatch(X,U,T,K,\alpha) \]
\[ L_X=\frac{1}{X^{'}}\sum_{x,p\in X^{'}}{H(p,p_{model}(y|x;\theta))} \]
\[ L_{U}=\frac{1}{L|U'|}\sum_{u,q\in U'}{||q-p_{model}(y|u;\theta)||_2^2} \]
\[ L=L_{X}+\lambda_U L_U \]
其中,\(H(p, q)\)表示分布p和q之间的交叉熵,\(T,K,\alpha,\lambda_U\)为超参数。
数据增强
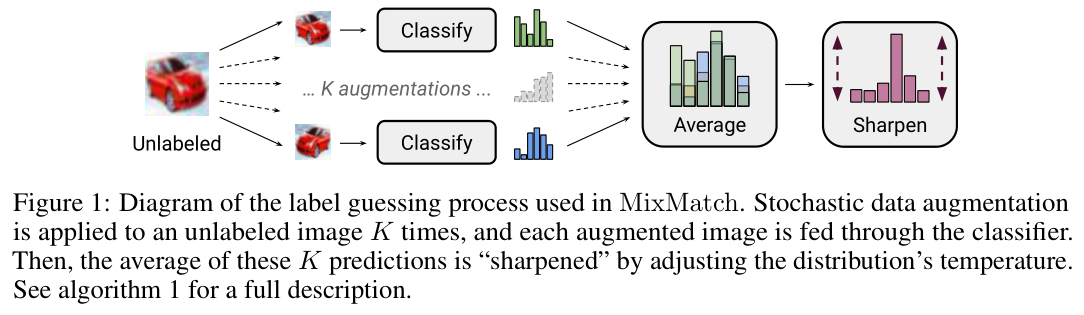
数据增强是减轻缺少有标数据影响的一种方法。类似于大部分半监督学习方法,我们同时对有标和无标数据进行数据增强。对有标数据进行一次数据增强,无标数据进行K次数据增强。这些无标数据增强后得到的结果进行“laebl guessing”获得\(q_b\)。
Label Guessing
对于单个无标样例,计算K次增强后类别预测分布的均值,这个得到的标签带入后续的无监督损失项中。 \[ \bar{q}_{b}=\frac{1}{K} \sum_{k=1}^{K} \operatorname{pmodel}\left(y \mid \hat{u}_{b, k} ; \theta\right) \]
Sharpening
通过sharpening方法进行熵最小化处理 \[ Sharpen(p, T):=\frac{P_i^{\frac{1}{T}}}{\sum_{j=1}^{L}{p_j^{\frac{1}{T}}}} \] 后续需要使用sharpen的输出作为模型预测的目标值,所以选择较低的T保证了模型可以产生低熵的预测。
MixUp
同时对有标数据和label guessing结果的无标数据进行MixUp。 \[ \lambda \sim Beta(\alpha, \alpha) \]
\[ \lambda'=max(\lambda, 1-\lambda) \]
\[ x'=\lambda'x_1+(1-\lambda')x_2 \]
\[ p'=\lambda' p_1 + (1-\lambda')p_2 \]
Experiments
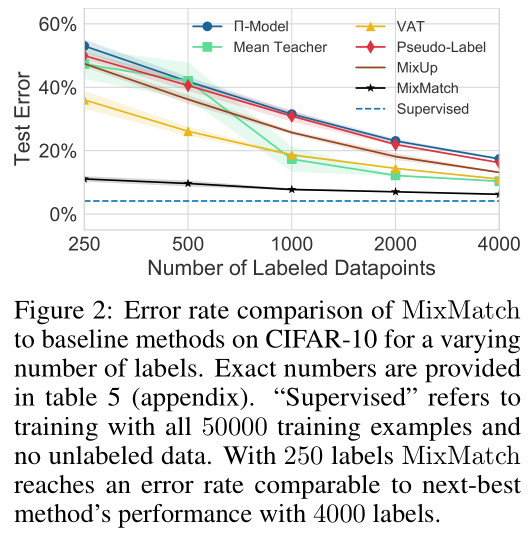
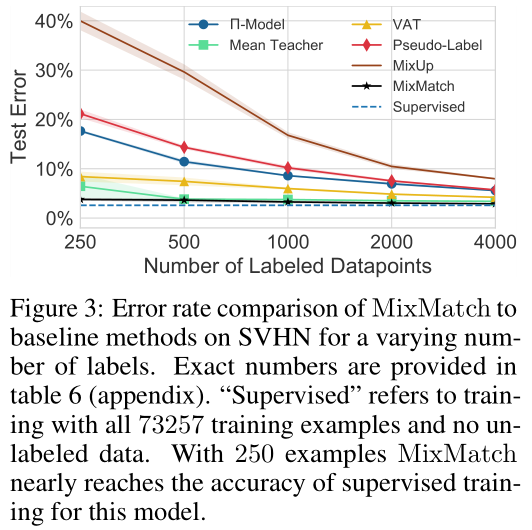
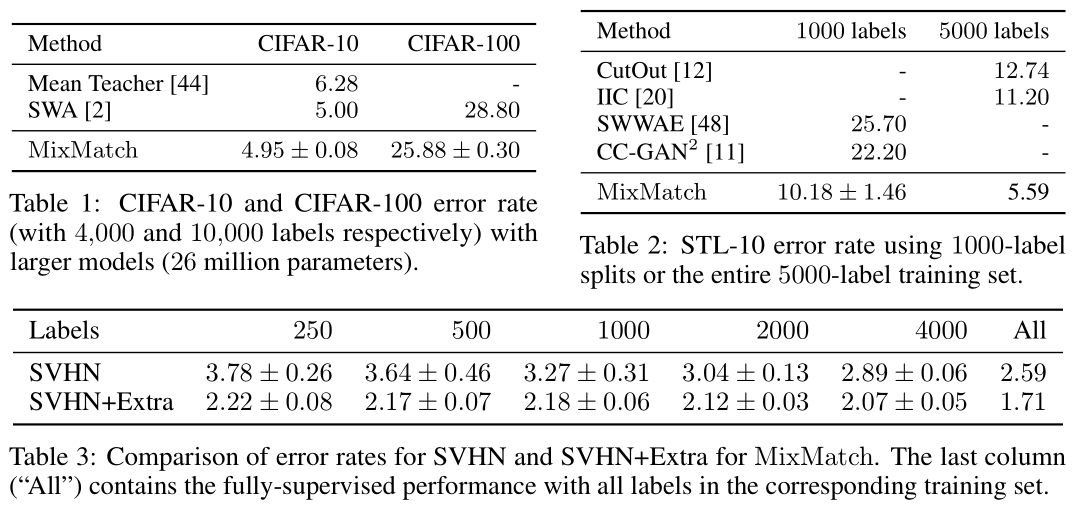
消融实验,感觉主要起作用的还是MixUp。
