Code: https://github.com/znxlwm/UGATIT-pytorch
UGATIT-自适应图层实例归一化下图像到图像转换 论文笔记
引入注意力机制,这里采用全局和平均池化的类激活图(Class Activation Map-CAM)来实现的,通过CNN确定分类依据的位置。 加入自适应图层实例归一化(AdaLIN),帮助注意力引导模型灵活控制形状和纹理变化量。
CAM 的意义就是以热力图的形式告诉我们,模型通过哪些像素点得知图片属于某个类别。 特征图经过 GAP 处理后每一个特征图包含了不同类别的信息,权重 w 对应分类时的权重。绘制热力图时,提取出所有的权重,往回找到对应的特征图,然后进行加权求和即可。 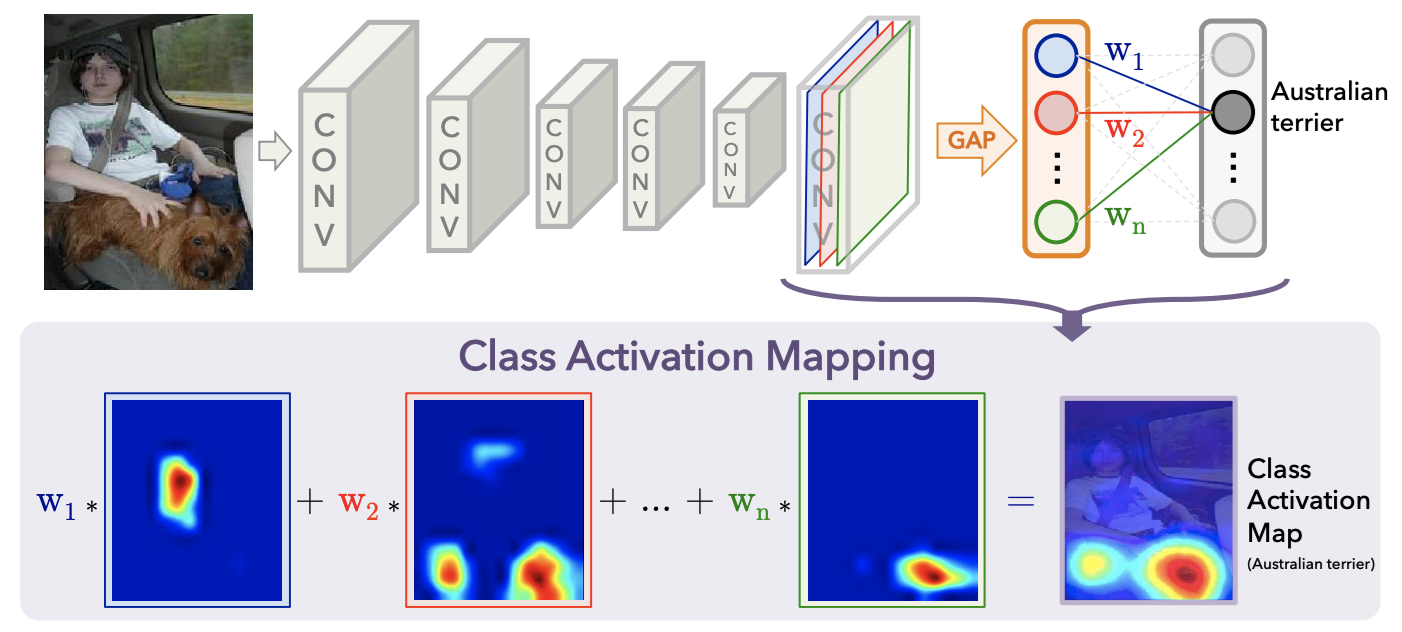
网络结构由一个生成器和两个判别器组成。 判别器的设计采用一个全局判别器(Global Discriminator)以及一个局部判别器(Local Discriminator)结合实现,所谓的全局判别器和局部判别器的区别就在于全局判别器对输入的图像进行了更深层次的特征压缩,最后输出的前一层。 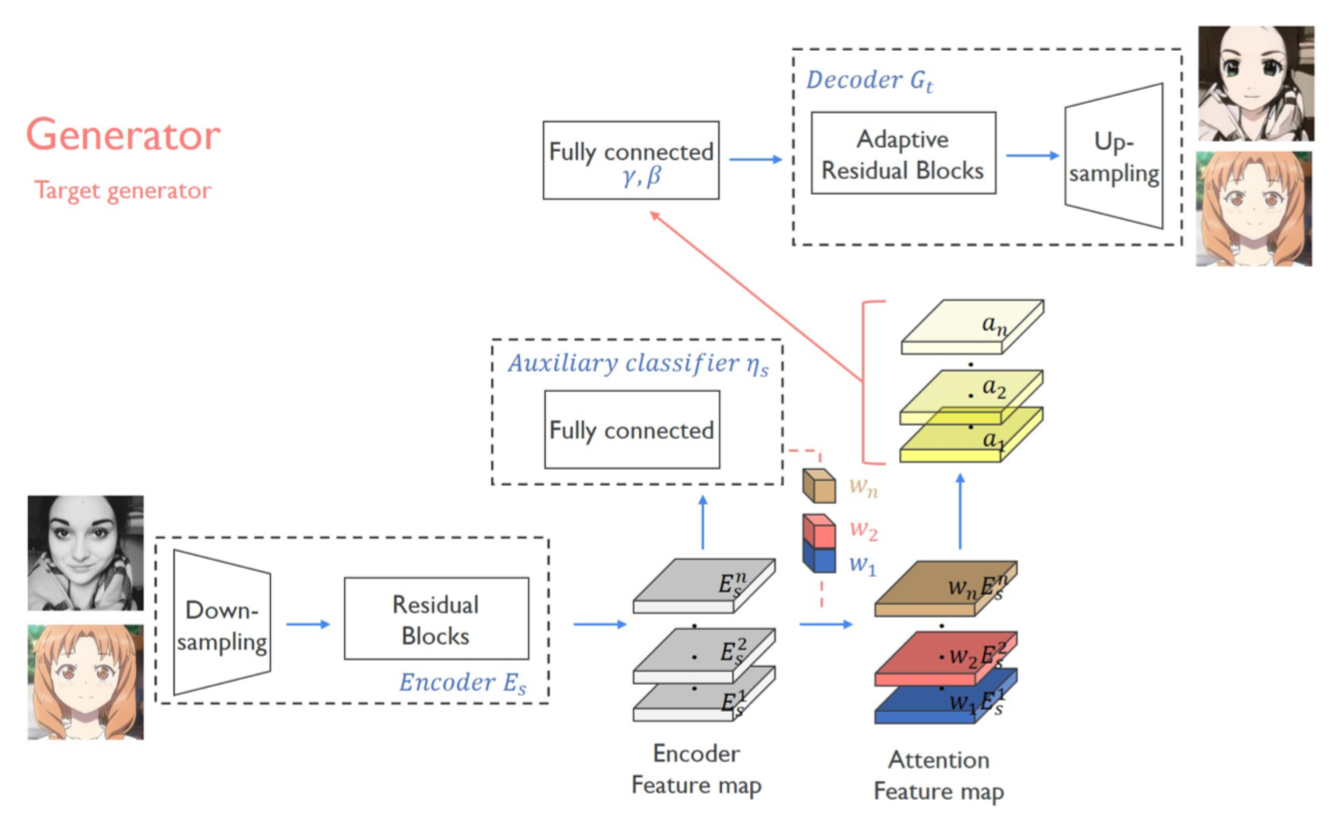
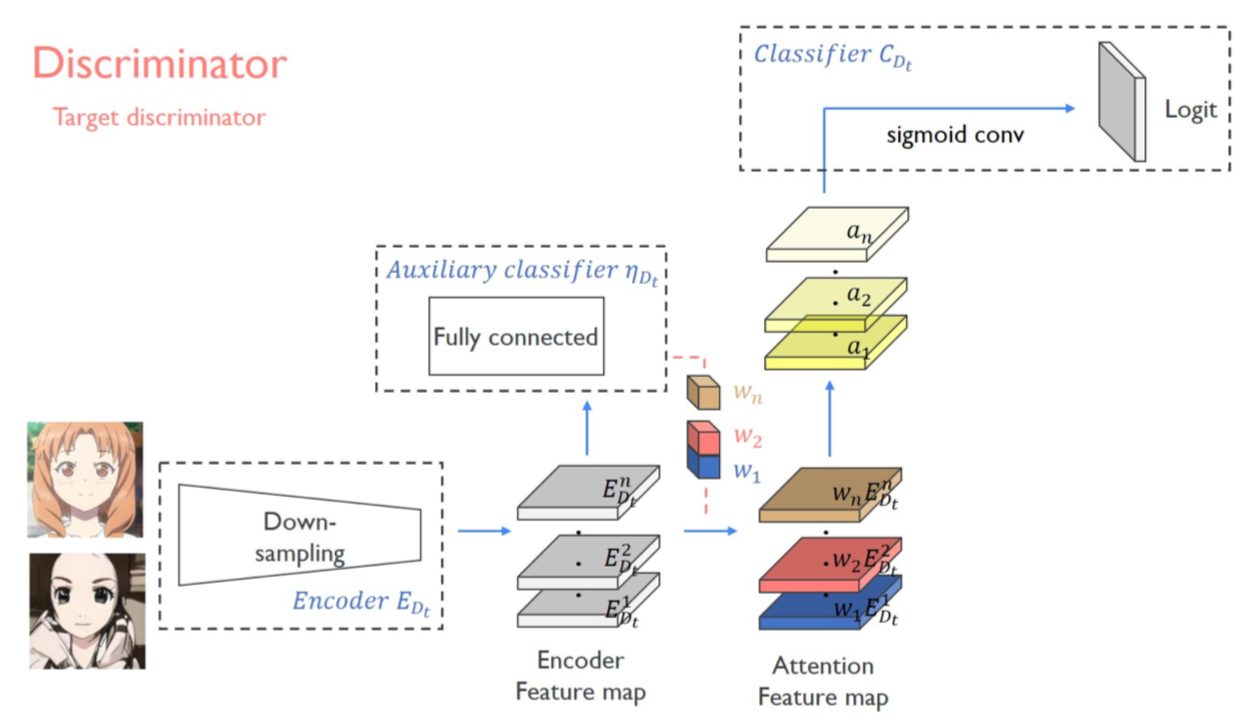
此处要提一下,在判别器中也加入了CAM模块,虽然在判别器下CAM并没有做域的分类,但是加入注意力模块对于判别图像真伪是有益的,文中给出的解释是注意力图通过关注目标域中的真实图像和伪图像之间的差异来帮助进行微调。
损失函数:
- GAN的对抗损失
- 循环一致性损失
- 身份损失(相同域之间不希望进行转换)
- CAM损失(生成器中对图像域进行分类,希望源域和目标域尽可能分开)
