Motivation
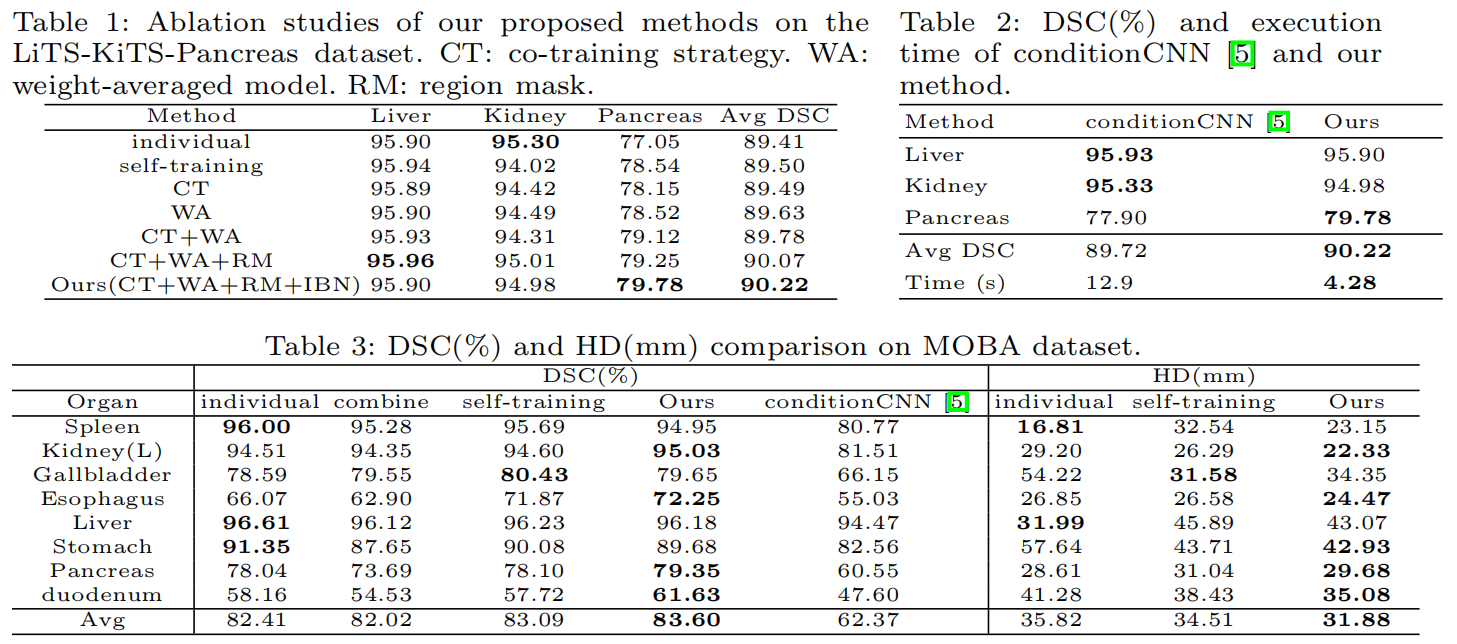
在同一幅图像上收集所有器官的完整注释通常是相当困难的,因为一些医学中心由于其自身的临床实践可能只注释了部分器官。
在大多数情况下,可以从一个训练集中获取单个或几个器官的注释,并从另一组训练图像中获取其他器官的注释。
一个直观的解决方案是使用训练数据集通过单独的模型分割每个器官。
这种方法不仅计算量高而且不能很好考虑不同器官之间的空间关系。
其他研究将不同数据集训练模型在其他数据集上生成伪标签,这种方法由于域不同容易产生大量噪声影响最终效果。
Methods
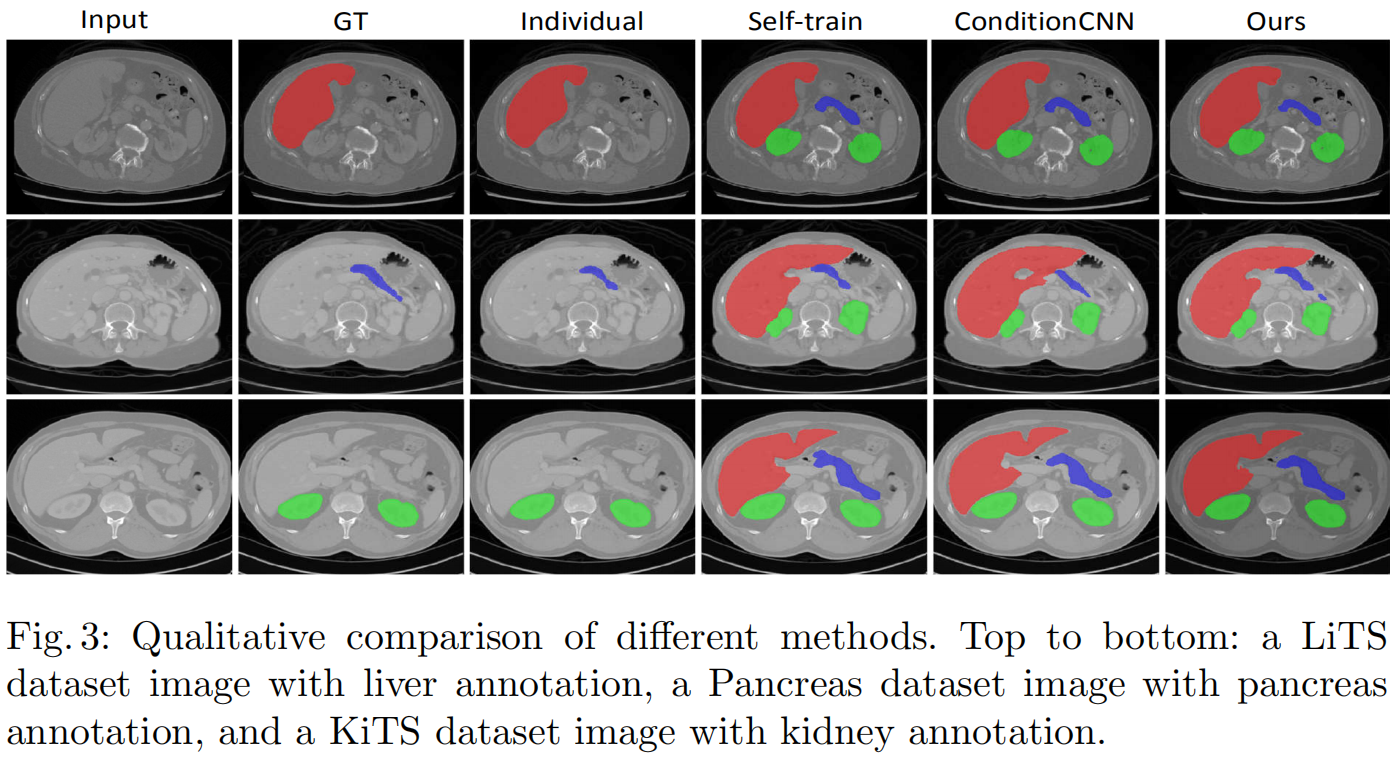
Pre-training single-organ and multi-organ models
单独对每个数据集训练一个模型,然后在其他器官上预测结果作为伪标签。
Co-training weight-averaged models for pseudo label regularization
两个相同结构的网络分别使用伪标签数据集进行训练。
另外使用上一轮训练的两个模型生成软伪标签加到原始数据集上训练另外两组模型。
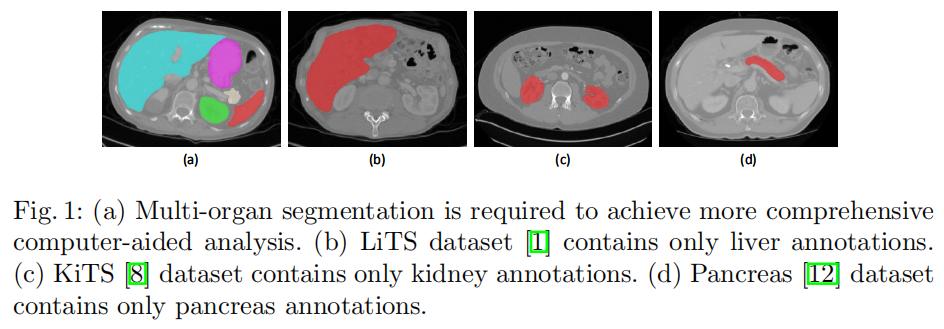
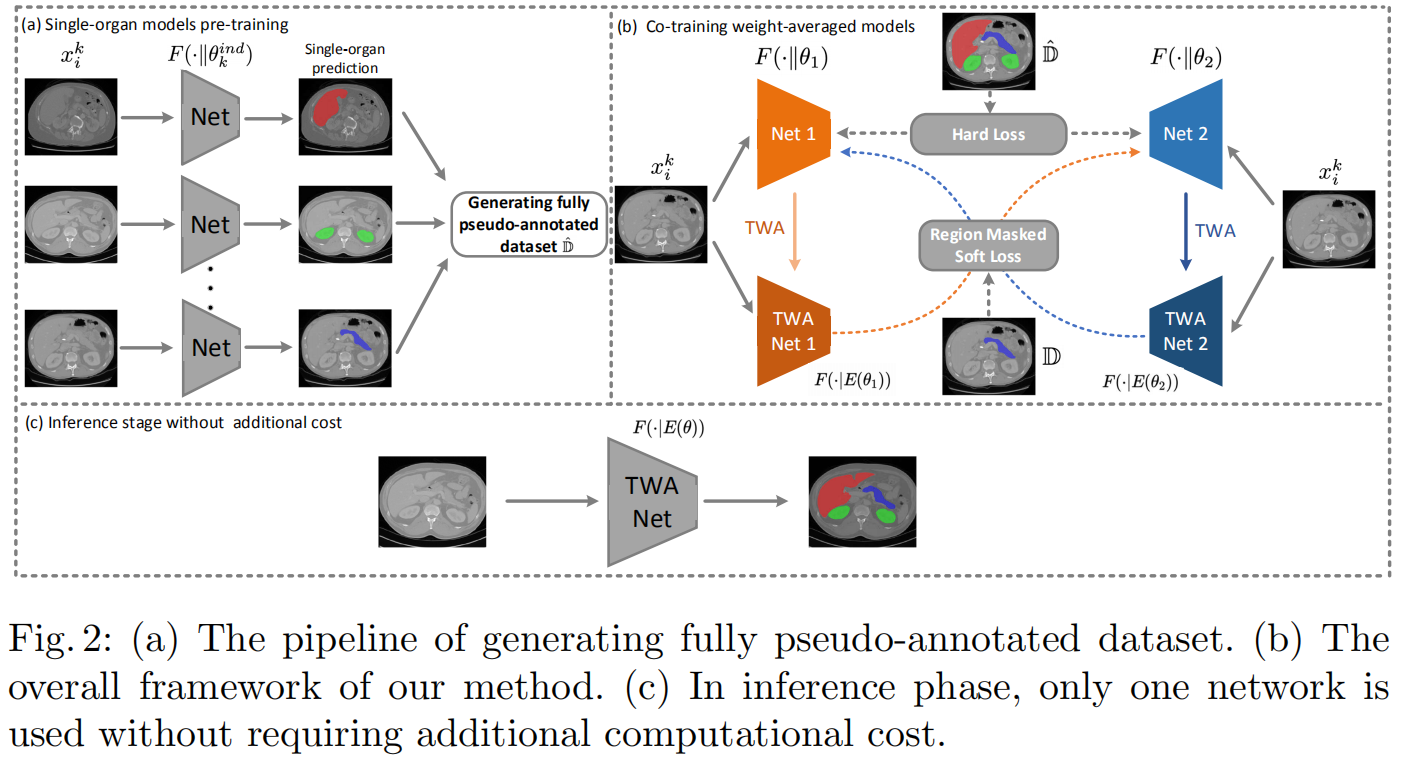
Experiments