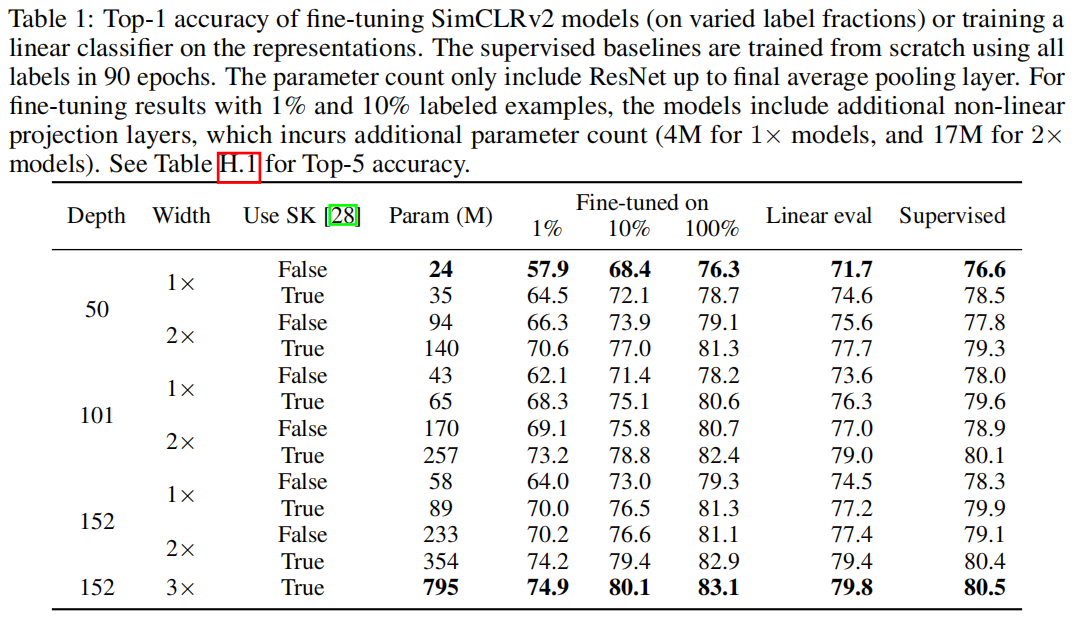
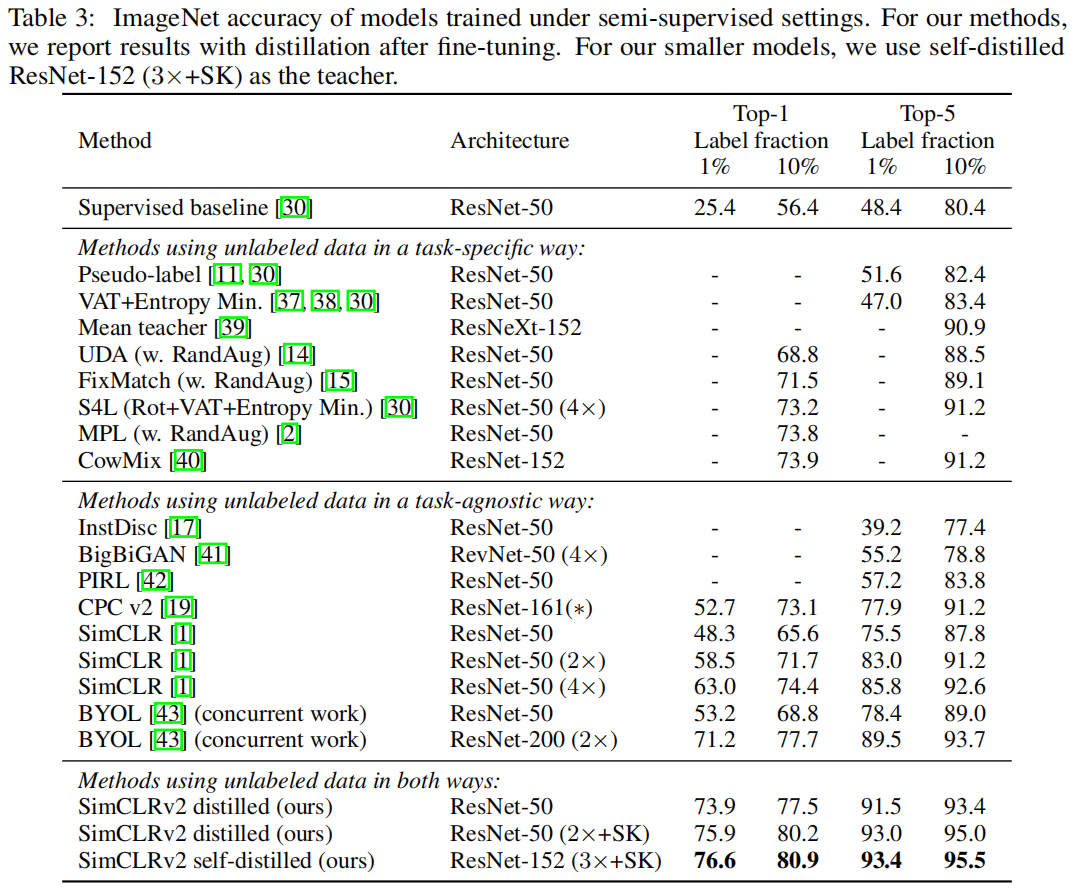
Code: https://github.com/google-research/simclr
Pdf: https://arxiv.org/abs/2006.10029
Motivation
通过与任务无关的方式使用未标记数据,作者发现,网络规模非常重要。
也就是说,使用大型(在深度和广度上)神经网络进行自监督的预训练和微调,可以大大提高准确率。
除了网络规模之外,作者表示,这项研究还为对比表示学习提供了一些重要的设计选择,这些选择有益于监督微调和半监督学习。
一旦卷积网络完成了预训练和微调,其在特定任务上的预测就可以得到进一步改善,并可以提炼成更小的网络。
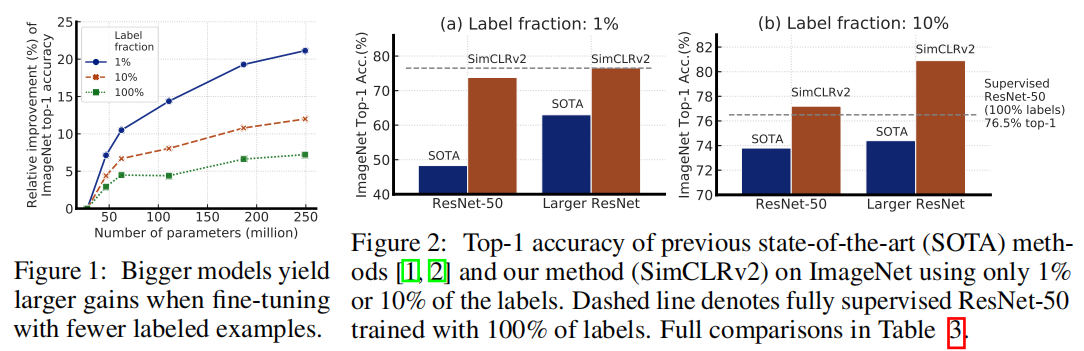
作者表示,对于这种范式的半监督学习,标记越少,就越有可能受益于更大的模型。
Methods
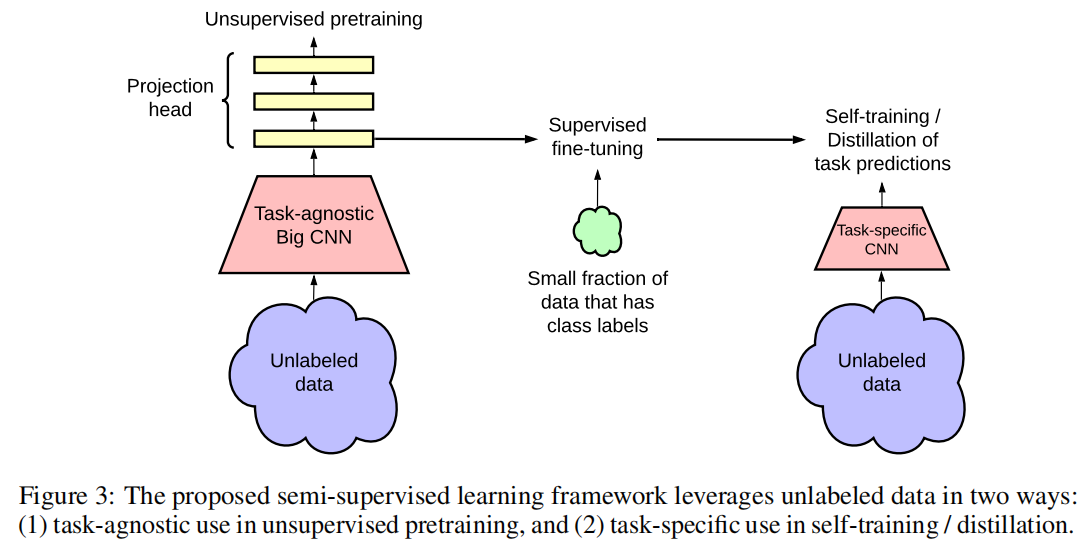
方法概括为三个主要步骤:预训练,微调和蒸馏:
- 使用未标记数据,以与任务无关的方式通过无监督的预训练来学习常规(可视)表示形式。
- 通过监督的微调使一般表示适合于特定任务。
- 使用未标记的数据,它以特定于任务的方式用于进一步改善预测性能并获得紧凑的模型。使用经过微调的教师网络中的推定标签在未标签数据上训练学生网络。
Experiments